https://www.kaggle.com/mlg-ulb/creditcardfraud
Credit Card Fraud Detection
Anonymized credit card transactions labeled as fraudulent or genuine
www.kaggle.com
안녕하세요! 오늘은 캐글의 Credit Card Fraud 데이터 세트를 이용해 신용카드 사기 검출 분류를 해보겠습니다.
진행 순서는 다음과 같습니다.
1. 데이터 뜯어보기
2. 학습용/테스트용 데이터 나누기
3. 데이터 전처리 후 모델 학습/예측/평가
3-1. 데이터 분포도 변환
3-2. 이상치 데이터 제거
4. 결과
1. 데이터 뜯어보기
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore")
%matplotlib inline
card_df=pd.read_csv('./datasets/creditcard.csv')
display(card_df.head(5))
display(card_df.shape)
display(card_df.columns)
데이터는 284807행, 31열로 이루어져 있고 칼럼 중 Class는 1이 사기이고 0이 정상 데이터를 뜻하는 target 값이고
Amount 피처는 신용카드 사용 금액을 의미합니다.
Time 피처는 의미가 없는 피처임으로 삭제해도 될 것 같습니다.
V1~V28 피처는 의미를 알 수 없습니다. 개인정보에 관련된 피처 같습니다.
결측치를 살펴보겠습니다.
print('결측치')
print(card_df.isna().sum())
결측치가 없는 깔끔한 데이터입니다.
데이터의 구조를 살펴봤으니 Class 피처와 Amount 피처에 대해 자세히 알아보겠습니다.
print('클래스 값 분포')
print(card_df.iloc[:,-1].value_counts())
Class 값을 보면 데이터가 상당히 불균형함을 확인할 수 있습니다.
당연히 사기인 데이터에 비해 정상인 데이터가 많기 때문입니다.
Amount 피처를 살펴보겠습니다.
import seaborn as sns
plt.figure(figsize=(10,5))
plt.xticks(range(0,30000,1000),rotation=60)
sns.distplot(card_df['Amount'])
카드 사용 금액이 0에서 1000달러 이하인 데이터가 대부분입니다.
신용 카드로 10만원 이상 쓰는 사람이 많지 않아 보입니다.
2. 학습용/테스트용 데이터 나누기
데이터를 뜯어봤으니 학습과 예측을 위해 데이터를 학습용과 테스트용으로 나눠야 합니다.
이때, 불균형한 데이터이기 때문에 Stratified 방식으로 나눠야 Class의 분포가 균등하게 나눠질 수 있습니다.
데이터의 원본을 유지한 채로 데이터를 전처리하고 나누기 위해 get_preprocessed_df 와 get_train_test_dataset 함수를 만들어 진행하였습니다.
from sklearn.model_selection import train_test_split
def get_preprocessed_df(df=None):
df_copy=df.copy()
df_copy.drop('Time',axis=1,inplace=True)
return df_copy
def get_train_test_dataset(df=None):
df_copy=get_preprocessed_df(df)
X_features=df_copy.iloc[:,:-1]
y_target=df_copy.iloc[:,-1]
X_train,X_test,y_train,y_test=train_test_split(X_features,y_target,test_size=0.3,random_state=0,stratify=y_target)
return X_train,X_test,y_train,y_test
X_train, X_test, y_train, y_test=get_train_test_dataset(card_df)
print('학습 데이터 레이블 값 비율')
print(y_train.value_counts()/y_train.shape[0]*100)
print('테스트 데이터 레이블 값 비율')
print(y_test.value_counts()/y_test.shape[0]*100)
테스트 세트를 전체의 30%가 되도록 나누었고 나누어진 target값의 비율은 위와 같습니다.
Straified 방식으로 나누었기에 매우 적었던 Class 값이 1인 데이터가 학습 데이터와 테스트 데이터에 0.172%와 0.173%로 큰 차이 없이 잘 분할된 것을 확인할 수 있습니다.
3. 데이터 전처리 후 모델 학습/예측/평가
각 데이터 전처리 후 모델의 예측 성능 평가를 매번 할 것이기 때문에
get_model_train_eval() 함수를 만들어 중복되는 작업을 편리하게 하도록 하였습니다.
평가는 정확도, 정밀도, 재현율, f1 스코어, roc-auc 스코어를 통해 진행하였습니다.
from sklearn.metrics import accuracy_score, precision_score, recall_score, confusion_matrix, f1_score, roc_auc_score
def get_model_train_eval(model, feature_train=None, feature_test=None, target_train=None, target_test=None):
model.fit(feature_train, target_train)
pred=model.predict(feature_test)
pred_proba=model.predict_proba(feature_test)[:,1]
confusion=confusion_matrix(target_test,pred)
accuracy=accuracy_score(target_test,pred)
precision=precision_score(target_test,pred)
recall=recall_score(target_test,pred)
f1=f1_score(target_test,pred)
roc_auc=roc_auc_score(target_test,pred_proba)
print('정확도: {0:.4f}, 정밀도: {1:.4f}, 재현율: {2:.4f}, F1: {3:.4f}, AUC: {4:.4f}'.format(accuracy,precision,recall,f1,roc_auc))
데이터 전처리 후의 성능을 비교해보기 위해 원본 데이터를 모델을 학습시키고 예측하고 모델의 예측 성능을 평가해보겠습니다.
모델은 분류에 대표적으로 쓰이는 로지스틱 회귀 모델과 최근 캐글에서 인기있는 앙상블 방법인 LightGBM 모델을 사용하였습니다.
from sklearn.linear_model import LogisticRegression
from lightgbm import LGBMClassifier
lr_clf=LogisticRegression()
lgbm_clf=LGBMClassifier(n_estimators=1000,num_leaves=64,n_jobs=-1,boost_from_average=False)
print('로지스틱 회귀 성능')
get_model_train_eval(lr_clf,X_train,X_test,y_train,y_test)
print('LightGBM 성능')
get_model_train_eval(lgbm_clf, X_train,X_test,y_train,y_test)
3-1. 데이터 분포도 변환
데이터 세트에서 Amount 피처의 값이 한쪽에 쏠려있는 상당히 불균형한 분포를 가지고 있었기 때문에
이러한 분포를 StandardScaler를 통해 정규 분포 형태로 변환해서 평가해보고,
데이터 분포도가 많이 왜곡되어 있을 경우 적용하는 중요 기법 중 하나인 로그 변환을 통해 변환하여 평가해보겠습니다.
① 정규화
from sklearn.preprocessing import StandardScaler
def get_preprocessed_df(df=None):
df_copy=df.copy()
scaler=StandardScaler()
amount_StandardScaled=scaler.fit_transform(df_copy['Amount'].values.reshape(-1,1))
df_copy.insert(0,'Amount_scaled',amount_StandardScaled)
df_copy.drop(['Time','Amount'],axis=1,inplace=True)
sns.distplot(df_copy['Amount_scaled'])
return df_copy
X_train, X_test, y_train, y_test=get_train_test_dataset(card_df)
Amount 피처값이 0에서 26000이 아닌 0에서 100으로 분포가 많이 줄어들었고
분포의 형태는 스케일링 전의 분포와 많이 유사한 것을 볼 수 있습니다.
Amount 피처값이 스케일링된 데이터 세트로 모델을 학습시키고 예측하고 모델의 예측 성능을 평가해보겠습니다.
from sklearn.linear_model import LogisticRegression
from lightgbm import LGBMClassifier
lr_clf=LogisticRegression()
lgbm_clf=LGBMClassifier(n_estimators=1000,num_leaves=64,n_jobs=-1,boost_from_average=False)
print('로지스틱 회귀 성능')
get_model_train_eval(lr_clf,X_train,X_test,y_train,y_test)
print('LightGBM 성능')
get_model_train_eval(lgbm_clf, X_train,X_test,y_train,y_test)
Amout 피처값을 정규화 한 데이터 세트를 이용한 모델의 성능은 원본 데이터를 이용한 모델에 비해 성능이 개선되지 않았음을 확인할 수 있습니다.
② 로그 변환
def get_preprocessed_df(df):
df_copy=df.copy()
amount_log_Scaled=np.log1p(df_copy['Amount'])
df_copy.insert(0,'Amount_Scaled',amount_log_Scaled)
df_copy.drop(['Time','Amount'],axis=1,inplace=True)
sns.distplot(df_copy['Amount_Scaled'])
return df_copy
X_train, X_test, y_train, y_test=get_train_test_dataset(card_df)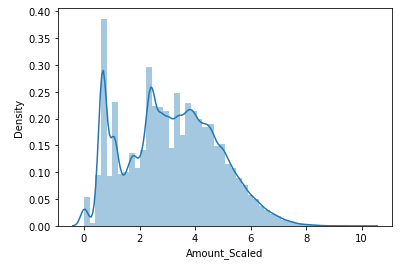
lr_clf=LogisticRegression()
lgbm_clf=LGBMClassifier(n_estimators=1000,num_leaves=64,n_jobs=-1,boost_from_average=False)
print('로지스틱 회귀 성능')
get_model_train_eval(lr_clf,X_train,X_test,y_train,y_test)
print('LightGBM 성능')
get_model_train_eval(lgbm_clf, X_train,X_test,y_train,y_test)
Amount 피처값을 로그 변환한 데이터 세트를 이용한 모델의 성능은 원본 데이터를 이용한 모델에 비해 성능이 약간씩 개선되었음을 확인할 수 있습니다.
3-2. 이상치 데이터 제거
이상치 데이터란 전체 데이터의 패턴에서 벗어난 이상 값을 가진 데이터를 말합니다.
이상치 데이터는 머신러닝 모델의 성능을 저하시킬 가능성이 높습니다.
이상치를 찾는 방법 중 대표적인 방법은 IQR 방법입니다.
IQR은 사분위 값의 편차를 이용하는 기법입니다.
사분위는 전체 데이터를 값이 높은 순으로 정렬하고 이를 Q1(25%), Q2(50%), Q3(75%), Q4(100%)로 4등분한 것을 말합니다.
여기서 IQR이란 Q1 ~ Q3 구간을 뜻합니다.
이상치 데이터는 IQR에 1.5를 곱해서 생성된 범위를 벗어난 데이터를 말합니다.
즉, Q1-(IQR*1.5) 에서 Q3+(IQR*1.5) 구간을 벗어나면 이상치 데이터로 간주합니다.
경우에 따라 1.5가 아닐 수 있지만 보통 1.5를 적용합니다.
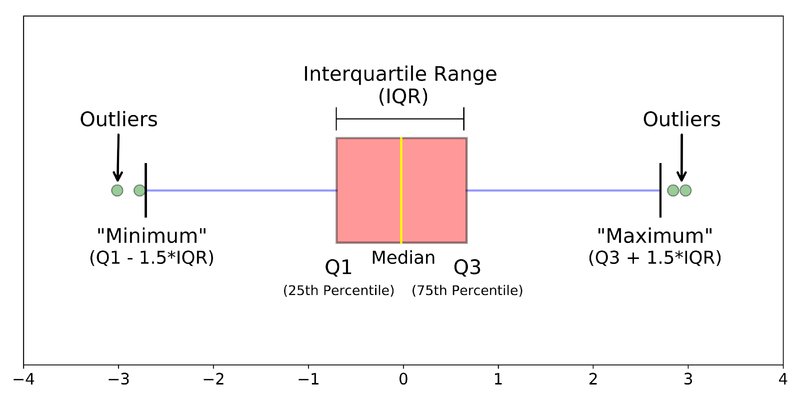
이제 이상치에 대해 이해하였으니 이상치 데이터를 IQR을 이용해 제거해 보겠습니다.
이상치 데이터를 제거하기 위해 먼저 어떤 피처의 이상치 데이터를 제거할 것인지가 필요합니다.
target값과 가장 상관성이 높은 피처들을 위주로 이상치를 제거하는 것이 좋습니다.
피처들의 상관도를 히트맵을 통해 알아보겠습니다.
plt.figure(figsize=(9,9))
corr=card_df.corr()
sns.heatmap(corr,cmap='RdBu')
맨 아래줄을 보면 Class와 다른 피처들의 상관관계를 볼 수가 있는데
음의 상관관계가 가장 높은 피처인 V14와 V17에 대해서 이상치를 검출하고 제거해 보겠습니다.
import numpy as np
def get_outlier(df,column,weight=1.5):
fraud=df[df['Class']==1][column]
quantile_25=np.percentile(fraud.values,25)
quantile_75=np.percentile(fraud.values,75)
iqr=quantile_75-quantile_25
iqr_weighted=iqr*weight
lowest_val=quantile_25-iqr_weighted
highest_val=quantile_75+iqr_weighted
outlier_index=fraud[(fraud<lowest_val)|(fraud>highest_val)].index
return outlier_index
outlier_index_V14=get_outlier(card_df,'V14',1.5)
print('V14 이상치 데이터 인덱스: ',outlier_index_V14)
outlier_index_V17=get_outlier(card_df,'V17',1.5)
print('V17 이상치 데이터 인덱스: ',outlier_index_V17)
V14의 이상치 데이터는 총 4개가 나왔고 V17은 나오지 않았습니다.
이제 V14의 이상치를 제거하고 모델에 적용하여 모델을 평가해보겠습니다.
def get_preprocessed_df(df):
df_copy=df.copy()
amount_log_Scaled=np.log1p(df_copy['Amount'])
df_copy.insert(0,'Amount_Scaled',amount_log_Scaled)
df_copy.drop(['Time','Amount'],axis=1,inplace=True)
outlier_index_V14=get_outlier(df_copy,'V14',1.5)
df_copy.drop(outlier_index_V14,axis=0,inplace=True)
return df_copy
print('V14 이상치 제거')
X_train, X_test, y_train, y_test = get_train_test_dataset(card_df)
print('로지스틱 회귀 성능')
get_model_train_eval(lr_clf,X_train,X_test,y_train,y_test)
print('LightGBM 성능')
get_model_train_eval(lgbm_clf, X_train,X_test, y_train, y_test)
전체적으로 성능이 많이 개선된 것을 볼 수 있는데 재현율이 로지스틱 회귀는 약 67%, LightGBM은 약 83%로 많이 개선된 것을 확인할 수 있습니다.
4. 결과
데이터 가공 유형에 따른 알고리즘의 예측 성능 평가 결과는 다음과 같습니다.

불균형한 분포를 가진 피처를 로그 변환을 통해 불균형한 분포를 감소시켜주고
target값과 상관관계가 높은 피처의 이상치 데이터를 제거한 결과가 가장 좋게 나왔습니다.
재현율에서 상당히 큰 성능 개선을 볼 수 있습니다.
사기 적발 모델의 경우 실제 사기인 경우(1) 을 정상(0) 이라고 판단하게 되면 큰 문제가 발생할 수 있기 때문에 재현율이 중요한 지표로 사용됩니다.
따라서, 데이터를 잘 가공해서 좋은 결과를 얻었다고 볼 수 있습니다!
이번 실습을 통해 데이터를 분석하고 전처리한 후 데이터에 맞는 머신러닝 알고리즘을 이용하여 학습, 예측, 성능 평가하는 전반적인 과정에 대해 이해할 수 있었습니다.
또한, 어떠한 데이터를 이용하는가가 중요한지를 느낄 수 있었습니다!
'머신러닝' 카테고리의 다른 글
| 차원 축소 (Dimension Reduction) - PCA, LDA (3) | 2021.07.14 |
|---|---|
| 앙상블 학습 (Ensemble Learning) - Stacking (0) | 2021.06.11 |
| 앙상블 학습 (Ensemble Learning) - Voting, Bagging, Boosting (0) | 2021.06.03 |
| 결정 트리 (Decision Tree) (0) | 2021.03.17 |
| 로지스틱 회귀 (Logistic Regression) (0) | 2021.03.15 |