*해당 포스팅은 한국어 임베딩(이기창 지음)을 공부하며 작성한 글입니다.
이전 포스팅에서 컴퓨터에 자연어를 이해시키기 위해 임베딩을 통해 벡터값을 생성해야 한다는 것을 알아봤습니다.
오늘은 그렇다면 이 벡터값에 자연어의 의미를 함축시키는 방법에 대해 알아보도록 하겠습니다.
그 방법은 자연어의 통계적 패턴 정보를 통째로 임베딩에 넣는 것입니다.
임베딩을 만들 때 쓰는 통계 정보는 크게 세 가지가 존재합니다.
어떤 단어가 많이 쓰이는지, 단어가 어떤 순서로 등장하는지, 문장에 어떤 단어가 같이 나타났는지와 관련한 정보입니다.
이제 이 세가지 통계 정보를 토대로 임베딩을 만드는 방법들에 대해 알아보겠습니다.
1. 어떤 단어가 많이 쓰이는가
1-1. 백오브워즈
1-2. TF-IDF
1-3. Deep Averaging Network
2. 단어가 어떤 순서로 등장하는가
2-1. 통계 기반 언어 모델
2-2. 뉴럴 네트워크 기반 언어 모델
3. 어떤 단어가 같이 쓰이는가
3-1. 분포 가정
3-2. 점별 상호 정보량 (PMI)
3-3. Word2Vec
1. 어떤 단어가 많이 쓰이는가
1-1. 백오브워즈
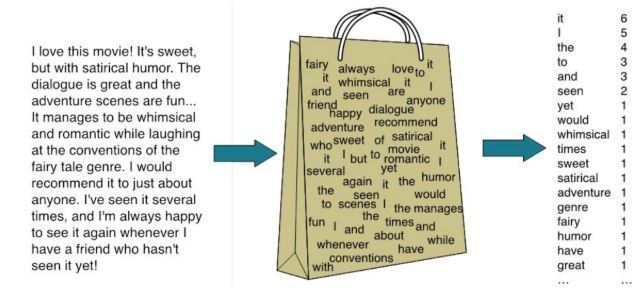
백오브워즈란 단어의 등장 순서에 상관없이 문서 내 단어의 등장 빈도를 임베딩으로 쓰는 기법을 말합니다.
문장을 단어들로 나누고 이들을 중복 집합에 넣어 임베딩으로 활용하는 것입니다.
이 기법의 핵심은 "저자가 생각한 주제가 문서에서의 단어 사용에 녹아 있다" 라는 가정입니다.
많이 쓰인 단어가 주제와 강한 연관이 있고 많이 쓰인 단어가 비슷하다면 문서의 주제가 비슷할 것이라 가정하는 겁니다.
이 기법은 단순해 보이는 기법이지만 정보 검색 분야에서 여전히 많이 쓰이고 있습니다.
예를 들어, "세계에서 가장 큰 국가" 라는 질문을 던졌을 때 질문을 백오브워즈 임베딩으로 변환하고
질문과 검색 대상 문서 임베딩 간 코사인 유사도를 구해 유사도가 가장 높은 문서를 사용자에게 노출시켜 줍니다.
하지만 단어 빈도를 그대로 임베딩으로 쓰는 것에는 큰 단점이 존재합니다.
예를 들어, 을/를, 이/가 같은 조사는 많이 등장하지만 이를 통해 문서의 주제를 추측하기는 어렵습니다.
이런 단점을 보완하기 위해 제안된 기법이 아래의 TF-IDF 입니다.
1-2. TF-IDF
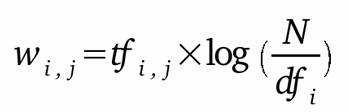
TF-IDF는 다음 수식과 같이 단어-문서 행렬에 가중치를 계산해 행렬 원소를 바꿉니다.
TF-IDF 역시 단어의 등장 순서는 고려하지 않기 때문에 보완된 백오브워즈 임베딩이라고 볼 수 있습니다.
여기서, TF는 Term Frequency로 어떤 단어가 특정 문서에 얼마나 많이 쓰였는지 빈도를 의미하고
DF는 Document Frequency로 특정 단어가 나타난 문서의 수를 의미합니다.
IDF는 Inverse DF로 전체 문서 수를 해당 단어의 DF로 나눈 뒤 로그를 취한 값입니다.
그 값이 클수록 적게 나타나는 특이한 단어라는 뜻입니다.
TF와 IDF를 곱한 값을 가중치로 설정해서 단어-문서 행렬의 행렬 원소 값을 바꾸는 것입니다.
TF-IDF의 원리는 특정 단어의 주제 예측 능력이 강할수록 가중치가 커지고 그 반대의 경우 작아지는 것입니다.
수식을 해석해보면, TF가 클수록, DF가 작을수록 가중치는 커지게 됩니다.
TF가 크다는 것은 특정 문서에 많이 나타난다는 것이고,
DF가 작다는 것은 여러 문서에 공통적으로 등장하지 않는다는 것을 의미합니다.
즉, 특정 문서에 많이 등장하지만 여러 문서에 공통적으로 등장하지 않는 단어는 특정 문서의 주제를 예측할 수 있는 능력이 강하다고 볼 수 있습니다.
1-3. Deep Averaging Network

DAN은 백오브워즈 기법의 뉴럴 네트워크 버전입니다.
이 기법 또한 단어가 쓰인 순서는 고려하지 않습니다.
해당 기법은 문장 임베딩을 입력받아 해당 문서가 어떤 범주인지 분류하는데 쓰입니다.
간단한 구조의 아키텍처임에도 성능이 좋아 현업에서 자주 쓰입니다.
2. 단어가 어떤 순서로 등장하는가
2-1. 통계 기반 언어 모델
언어 모델이란 단어 시퀀스에 확률을 부여하는 모델입니다.
언어 모델은 백오브워즈와 달리 시퀀스 정보를 명시적으로 학습합니다.
따라서 백오브워즈의 대척점에 있다고 말할 수 있습니다.
통계 기반 언어 모델은 말뭉치에서 해당 단어 시퀀스가 얼마나 자주 등장하는지 빈도를 세어 학습합니다.
잘 학습된 언어 모델이 있다면 어떤 문장이 그럴듯한 지, 주어진 단어 시퀀스 다음 단어는 무엇이 오는 게 자연스러운지 알 수 있습니다.
누명을 쓰다 → 0.41
누명을 당하다 → 0.02
위와 같이 자연스러운 문장에 더 높은 확률을 부여합니다.
n-gram이란 n개 단어를 뜻하는 용어이며 n-gram에 기반한 언어 모델을 의미하기도 합니다.
말뭉치 내 단어들을 n개씩 묶어서 그 빈도를 학습했다는 뜻입니다.
2-gram은 바이그램이라고 부르며, 3-gram은 트라이그램이라고 부릅니다.
n-gram을 통해 문법적으로나 의미적으로 결함이 없는 문장이 말이 되지 않는 취급되는 문제를 일부 해결할 수 있습니다.
예를 들어, "내 마음 속에 영원히 기억될 명작이다"라는 문장이 문서에서 나타나지 않았고 "내 마음 속에 영원히 기억될" 이라는 문장이 1번 등장했다고 가정하면,
"내 마음 속에 영원히 기억될" 뒤에 "명작이다"라는 단어가 나올 확률을 조건부 확률을 통해 구하면,
Count(내, 마음, 속에, 영원히, 기억될, 명작이다) / Count(내, 마음, 속에, 영원히, 기억될) 인데 분자가 0이므로 확률이 0이 되는 문제가 발생합니다.
이를 직전 n-1개 단어의 등장 확률로 전체 단어 시퀀스 등장 확률을 근사하는 방법을 통해 해결할 수 있습니다.
이는 한 상태의 확률은 그 직전 상태에만 의존한다는 마코프 가정에 기반한 것입니다.
바이그램 모델로 근사할 경우, "명작이다" 직전의 1개 단어만 보고 전체 단어 시퀀스의 등장 확률을 근사할 수 있다는 것입니다.
즉, Count(최고의, 명작이다) / Count(최고의) 를 통해 근사하는 것입니다. 이를 수식화하면 다음과 같습니다.
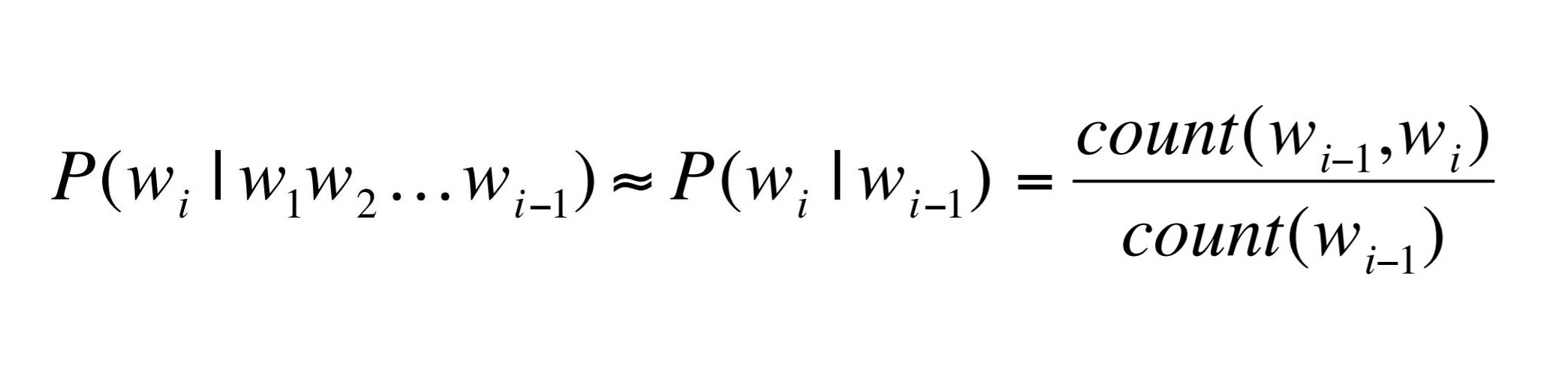
그리고 "내 마음 속에 영원히 기억될 명작이다" 라는 문장이 등장할 확률을 바이그램으로 구하면
연쇄 법칙과 같이 P(내)xP(마음ㅣ내)xP(속에ㅣ마음)x ... xP(명작이다ㅣ기억될) 로 구할 수 있습니다.
이를 수식화하면 다음과 같습니다.

n-gram 모델은 바이그램 모델의확장판으로 직전 1개의 단어만 참고하는 것이 아니라 직전 n-1개의 단어를 참고하는 것입니다.
이렇게 n-gram 모델에도 아직 문제는 남아 있습니다.
데이터에 한 번도 등장하지 않는 n-gram이 존재할 때 예측 단계에서 문제가 발생할 수 있습니다.
만약 영원히라는 단어가 데이터에 한 번도 등장하지 않는다고 가정하면,
P(영원히ㅣ속에) = 0 이 되고 "내 마음 속에 영원히 기억될 명작이다" 라는 자연스러운 문장이 등장할 확률을 0으로 부여하게 되는 문제가 발생합니다.
이를 위해 백오프, 스무딩 등의 방식이 제안됐습니다.
백오프란 n-gram 등장 빈도를 n보다 작은 범위의 단어 시퀀스 빈도로 줄여 근사하는 방식을 말합니다.
n을 크게 할수록 등장하지 않는 케이스가 많아질 가능성이 높기 때문입니다.
예를 들면, 6-gram 모델에서 등장 빈도가 0인 문장에 대해서 백오프 방식으로 n을 3으로 줄여서 근사할 수 있습니다.
Count(내 마음 속에 영원히 기억될 명작이다) = A·Count(영원히 기억될 명작이다) + B 라고 근사할 수 있습니다.
이 때, A와 B는 실제 빈도와의 차이를 보정해주는 파라미터입니다.
물론 빈도가 1 이상인 6-gram에 대해서는 백오프하지 않고 해당 빈도를 그대로 n-gram 모델 학습에 사용하면 됩니다.
스무싱은 등장 빈도 표에 모두 k만큼 더하는 기법입니다.
이를 Add-k 스무싱이라고 부르기도 합니다.
빈도가 0인 단어 시퀀스가 없도록 만드는 것입니다.
만약 k를 1로 설정한다면 이를 특별히 라플라스 스무싱이라고 부릅니다.
스무싱을 시행하면 높은 빈도를 가진 문자열 등장 확률을 일부 깎고 전혀 등장하지 않는 케이스들에는 작게나마 확률을 부여하게 됩니다.
2-2. 뉴럴 네트워크 기반 언어 모델
통계 기반 언어 모델은 단어들의 빈도를 세어서 학습합니다.
이를 뉴럴 네트워크로 학습할 수도 있습니다.
뉴럴 네트워크는 입력과 출력 사이의 관계를 유연하게 포착해낼 수 있고, 그 자체로 확률 모델로 기능할 수 있기 때문이다.
뉴럴 네트워크 기반 모델은 주어진 단어 시퀀스를 가지고 다음 단어를 맞추는 과정에서 학습됩니다.
학습이 완료되면 이들 모델의 중간 혹은 말단 계산 결과물을 단어나 문장의 임베딩으로 활용합니다.
ELMo, GPT 등의 모델이 여기에 해당합니다.

마스크 언어 모델은 문장 중간에 마스크를 씌워 놓고, 해당 마스크에 어떤 단어가 올지 예측하는 과정에서 학습됩니다.
언어 모델 기반 기법은 단어를 순차적으로 입력받아 단어를 예측하기 때무에 일방향적이고,
마스크 언어 모델은 문장 전체를 보고 중간에 있는 단어를 예측하기 때문에 양방향 학습이 가능합니다.
이러한 이유 덕분에 마스크 언어 모델이 기존 언어 모델 기법들에 비해 임베딩 품질이 좋습니다.
BERT가 여기에 속합니다.

3. 어떤 단어가 같이 쓰이는가
3-1. 분포 가정
자연어 처리에서 분포란 특정 범위 내에 동시에 등장하는 이웃 단어 또는 문맥의 집합을 가리킵니다.
어떤 단어 쌍이 비슷한 문맥 환경에서 자주 등장한다면 그 의미 또한 유사할 것이라는 게 분포 가정의 전제입니다.
예를 들어 알아보면, "빨래" 라는 단어가 "청소", "요리", "물", "속옷"과 같이 등장하고
"세탁" 이라는 단어가 "청소", "요리", "물", "옷"과 같이 등장한다고 했을 때,
분포 가정을 적용해 유추해 보면 "빨래"와 "세탁"이 비슷한 의미를 가지고 있다고 유추해볼 수 있습니다.
같이 등장하는 단어들이 비슷하기 때문입니다.
또한 "빨래"가 "청소", "요리", "물", "속옷"과 관계를 지닐 가능성이 존재한다고 볼 수 있습니다.
하지만 개별 단어의 분포 정보와 그 의미 사이에 논리적으로 직접적인 연관성이 있다고 보기는 어렵습니다.
분포 정보와 의미 사이에 어떤 관계가 있는지 언어학적 관점에서 살펴보겠습니다.
① 형태소
언어학에서 형태소란 의미를 가지는 최소 단위를 말합니다.
언어학자들은 형태소를 계열 관계를 기준으로 분석합니다.
계열 관계는 해당 형태소 자리에 다른 형태소가 대치되어 쓰일 수 있는가를 따지는 것입니다.
예를 들면, "철수가 밥을 먹는다" 라는 문장에서 "철수" 자리에 "영희" 라는 단어가 올 수 있고,
"밥" 대신 "빵"이 올 수 있음을 보면 "철수"와 "밥"이 형태소 자격을 가집니다.
언어학자들이 특정 타깃 단어 주변의 문맥 정보를 바탕으로 형태소를 확인한다는 것을 보면 말뭉치의 분포 정보와 형태소가 밀접한 관계를 이루고 있다는 것을 알 수 있습니다.
즉, 분포 정보와 의미가 관계를 가진다고 볼 수 있는 것입니다.
② 품사
언어학에서 품사란 단어를 문법적 성질의 공통성에 따라 언어학자들이 몇 갈래로 묶어 놓은 것입니다.
품사의 분류 기준은 기능, 의미, 형식 등 세 가지입니다.
예문을 통해 알아보겠습니다.
- 이 샘의 깊이가 얼마나?
- 저 산의 높이가 얼마나?
- 이 샘이 깊다.
- 저 산이 높다.
기능은 한 단어가 문장 가운데서 다른 단어와 맺는 관계를 가리킵니다.
위의 예시에서 기능이 같은 단어 부류를 묶으면 주어로 쓰인 깊이와 높이가 묶이고, 서술어로 사용된 깊다와 높다가 같이 묶이게 됩니다.
의미란 단어의 형식적 의미를 나타냅니다.
품사 분류에서는 어휘적 의미보다 형식적 의미를 중요하게 따집니다.
어떤 단어가 사물의 이름을 나타내느냐, 움직임이나 성질, 상태를 나타내느냐 하는 것으로 분류합니다.
위의 예시에서 깊이와 높이를 묶고, 깊다와 높다를 묶을 수 있습니다.
형식이란 단어의 형태적 특징을 의미합니다.
위의 예시에서 깊이와 높이는 변화하지 않지만 깊다와 높다는 깊었다 높았다와 같이 여러 모습으로 변화할 수 있습니다.
이 기준으로 깊이와 높이를 묶을 수 있고 깊다와 높다를 같은 덩어리로 묶을 수 있습니다.
하지만 실제 품사를 분류할 때는 여러 어려움이 따릅니다.
의미나 형태는 품사 분류의 결정적인 기준이 될 수 없습니다.
예를 들어, "공부하다"와 "공부"에서 "공부하다"는 움직임을 나타내는 동사로,
"공부"는 사물의 이름을 의미하는 명사로 분류할 수 있지만 "공부"라는 단어에 움직임을 나타내지 않는다고 단정 지을 수 없습니다.
즉 의미가 품사 분류의 결정적인 기준이 될 수 없습니다.
형태도 마찬가지로 형태는 같지만 기능과 의미가 달라질 수 있습니다.
언어학자들이 꼽는 결정적인 기준은 기능이라고 합니다.
그런데 한국어를 비롯한 많은 언어에서 어떤 단어의 기능이 그 단어의 분포와 매우 밀접한 관계를 가지고 있다고 합니다.
형태소의 경계를 정하거나 품사를 나누는 것과 같은 다양한 언어학적 문제는 말뭉치의 분포 정보와 깊은 관계를 맺고 있고,
이 덕분에 임베딩에 분포 정보를 함축하게 되면 해당 벡터에 해당 단어의 의미를 함축시킬 수 있게 되는 것입니다.
3-2. 점별 상호 정보량 (PMI)
점별 상호 정보량은 두 확률 변수 사이의 상관성을 계량화하는 단위입니다.
두 확률 변수가 완전히 독립인 경우 그 값이 0이 됩니다.
점별 상호 정보량은 Pointwise Mutual Information이며 PMI라고 부릅니다.
PMI공식은 다음과 같습니다.

PMI는 두 단어의 등장이 독립일 때 대비해 얼마나 자주 같이 등장하는지를 수치화한 것입니다.
이렇게 구축한 PMI 행렬의 행 벡터 자체를 해당 단어의 임베딩으로 사용할 수도 있습니다.
PMI 값이 높을수록 두 단어 사이의 상관성이 높고 같이 등장할 확률이 높다고 볼 수 있습니다.
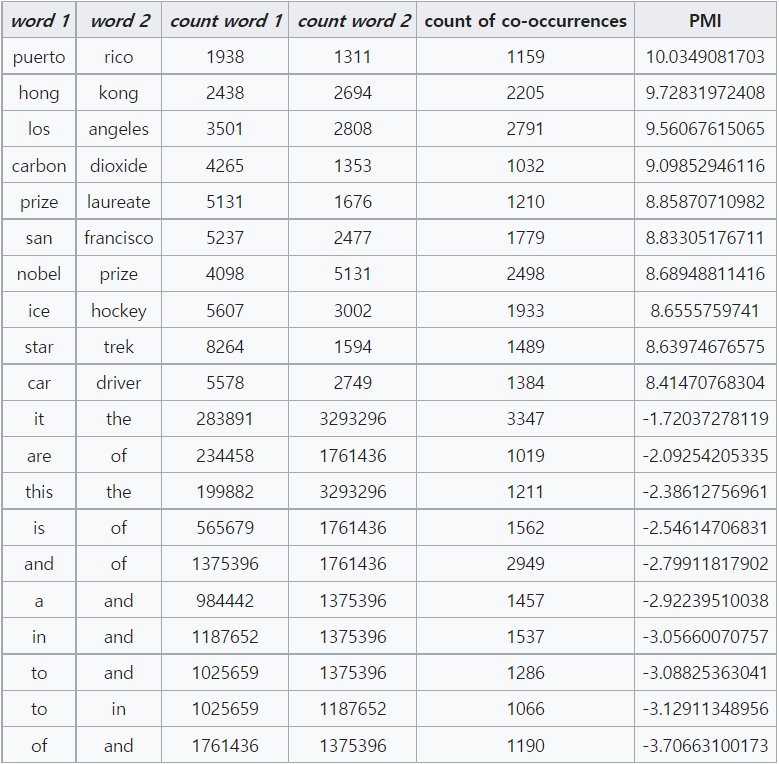
위의 표를 보면 puerto와 rico나 hong과 kong 등 같이 쓰이는 단어의 쌍은 PMI 값이 매우 높음을 확인할 수 있습니다.
(위의 표에서 전체 단어의 수는 50,000,952개 이고 log는 밑이 e인 자연로그를 사용했습니다.)
3-3. Word2Vec
Word2Vec 기법은 구글 연구팀이 발표한 분포 가정의 대표적인 모델입니다. 그 기본 구조는 다음과 같습니다.
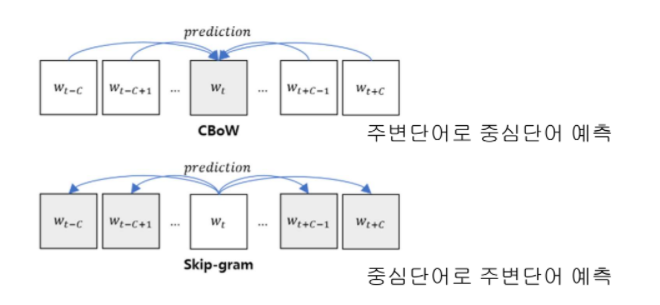
CBoW (Continuous Bag of Words) 모델은 주변 단어들을 통해 타깃 단어를 맞추는 과정에서 학습되고,
Skip-gram 모델은 타깃 단어를 가지고 주변 단어가 무엇일지 예측하는 과정에서 학습됩니다.
둘 다 특정 타깃 단어 주변의 문맥, 즉 분포 정보를 임베딩에 포함합니다.
이렇게 벡터값에 어떻게 자연어의 의미를 함축시킬 수 있는 방법들에 대해 알아봤습니다.
앞으로는 한국어를 전처리하는 법과 다양한 임베딩 기법에 대해 더욱 자세히 알아보도록 하겠습니다 : )
'자연어처리 (NLP)' 카테고리의 다른 글
| 임베딩(Embedding)이 뭐지? (3) | 2021.07.28 |
|---|