*해당 포스팅은 핸즈온 머신러닝(2판) 교재를 공부하며 작성한 글입니다.
안녕하세요! 오늘은 머신러닝의 대표적인 지도학습의 회귀 중 선형 회귀에 대해 알아보겠습니다.
1. 선형 회귀
1-1. 경사 하강법
1-1-1. 학습률
1-1-2. 과정
1-1-3. 경사 하강법의 종류와 문제점
1-2. 규제가 있는 선형 모델
1-3-1. 릿지 회귀
1-3-2. 라쏘 회귀
1-3-3. 엘라스틱넷
1. 선형 회귀
회귀는 지도학습인데 지도학습이란 훈련 데이터로부터 하나의 함수를 유추해내는 방법입니다.
그중 선형 회귀란 데이터들을 가장 잘 대변할 수 있는 "직선"을 찾아 새로운 데이터 값을 넣었을 때의 결괏값을 예측할 수 있도록 하는 것입니다.

이 선형 함수 모델 (초록 점선) 의 식은 다음과 같습니다.
H(x)=wx+b
H(x)는 예측 값을 나타내고 w와 b는 모델 파라미터, x는 입력 데이터 값입니다.
이 모델을 훈련 데이터로 훈련시켜서 적정 파라미터 값을 찾는 것이 목표입니다.
이때 적정 파라미터는 각 오차의 제곱을 평균 낸 값(MSE)인 Cost가 최소일 때의 파라미터를 뜻합니다.
선형 회귀의 비용함수는 다음과 같습니다.

예측값에서 실제값을 뺀 H(x)-y 가 오차를 나타냅니다.
그렇다면 이 오차가 최소인 지점은 어디일까요?
그 지점을 구하는 방법 중 가장 대표적인 방법인 경사 하강법이 있습니다.
1-1. 경사 하강법

노란 점이 Cost가 최소인 지점입니다. 이 지점을 향해 파라미터 값이 반복적으로 수정됩니다.
1-1-1. 학습률
경사하강법에서 중요한 파라미터는 스텝의 크기인데 이는 학습률(Learning step) 하이퍼파라미터로 결정됩니다.
이때 학습률이 너무 작으면 최솟값을 찾기 위해 반복이 많이 진행되어야 하므로 시간이 오래 걸립니다.
학습률이 너무 클 경우에는 반대편으로 왔다 갔다 할 수 있기 때문에 최솟값에 도달하지 못할 수 있습니다.
그렇기 때문에 적절한 학습률을 설정할 필요가 있습니다.

1-1-2. 과정
Cost를 줄이기 위해서 Cost가 줄어드는 방향으로 w와 b를 수정해야 합니다.
w를 수정하는 식은 다음과 같습니다.

Cost를 w에 대해 미분한 값에 학습률(알파)을 곱한 값을 빼주면 됩니다.
이때 기울기가 음수인 부분에서는 음수를 빼주게 되므로 스텝의 크기가 점점 작아지고
기울기가 양수인 부분은 양수를 빼주게 되므로 스텝의 크기가 점점 작아지며 최솟점(노란점)으로 수렴하게 됩니다.
반복을 통해 Cost가 최소일 때의 w가 위에서 말한 적정 파라미터 값입니다.
b도 이와 같은 방법으로 수정을 반복해서 적정 값을 구할 수 있습니다.
이렇게 구한 식 (y=wx+b) 은 이제 훈련 데이터를 대변하는 식이라고 말할 수 있습니다.
1-1-3. 경사하강법의 종류와 문제점
- 종류
배치 사이즈에 따라 경사 하강법을 세 종류로 나눌 수 있습니다.
배치 사이즈란 기울기 수정 시 훈련세트를 몇 개씩 묶어서 사용할지에 대한 정보입니다.
예를 들어 훈련 데이터 사이즈 : 50000, 배치 사이즈 : 10000 이면 5개의 묶음이 나오므로 기울기는 5번 업데이트됩니다.
①. 배치 경사 하강법
배치 사이즈가 훈련 데이터 사이즈와 동일한 경사 하강법입니다.
항상 같은 데이터에 대해 경사를 구하기 때문에 수렴이 안정적입니다.
하지만, 전체 훈련 세트를 한 번에 처리하기 때문에 메모리가 많이 필요하며 시간이 많이 소요됩니다.
②. 확률적 경사 하강법
배치 사이즈가 1인 경사 하강법입니다.
전체 훈련 세트 중 랜덤하게 하나의 데이터를 선택해 기울기를 업데이트하기 때문에 확률적이라고 합니다.
1개의 데이터마다 비용 함수의 기울기는 다르기 때문에 각각의 데이터에 대해 미분을 수행하면 기울기의 방향이 매번 크게 변화되어 불안정합니다.
무작위성은 지역 최솟값에서 탈출시켜서 좋지만 알고리즘을 전역 최솟값에 다다르지 못하게 한다는 단점이 있습니다.
이를 해결하는 방법은 학습률을 점진적으로 감소시키는 것입니다.
시작할 때는 학습률을 크게 하고 점차 작게 줄여서 전역 최솟값에 도달하게 합니다.
전역 최솟값과 지역 최솟값 무엇인가는 아래 문제점 부분의 사진을 보면 확인하실 수 있습니다.
③. 미니배치 경사 하강법
배치 경사 하강법과 확률적 경사 하강법의 절충안으로, 전체 훈련세트를 1~M 사이의 적절한 배치 사이즈(미니배치)로 나누어 학습하는 것입니다.
확률적 경사 하강법보다 덜 불규칙하게 움직이므로 비교적 안정적이지만 지역 최솟값에서 빠져나오기는 더 힘들 수도 있습니다.
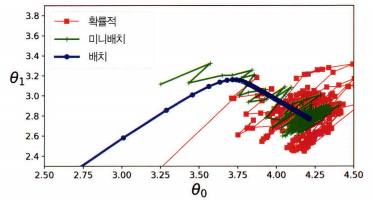
모두 최솟값 근처로 향하지만 배치 하강법의 경로가 실제로 최솟값에서 멈춘 반면 확률적 경사 하강법과 미니배치 경사 하강법은 근처에서 맴돌고 있음을 확인할 수 있습니다.
그렇지만 배치 경사 하강법에서는 매 스텝에서 많은 시간이 소요됨을 확인할 수 있고
확률적 경사 하강법과 미니배치 경사 하강법도 적절한 학습 스케줄을 사용하면최솟값에 도달함을 알 수 있습니다.
훈련 샘플의 수나 특성 수에 따라 적절한 방법을 이용하면 됩니다.
- 문제점

비용함수가 다음과 같이 매끈한 볼록함수가 아닌 경우도 있습니다.
이때 왼쪽에서 시작하게 되면 전체의 최솟값이 아닌 지역 최솟값에 수렴하게 됩니다.
또한 오른쪽에서 시작하게 되면 평평한 부분을 지나기 위해 시간이 오래 걸리고 일찍 멈추게 되어 전역 최솟값에 도달하지 못합니다.
하지만! 선형 회귀의 비용함수인 MSE 함수는 매끈한 볼록함수이기 때문에 전역 최솟값에 도달하지 못할 거라는 걱정은 하지 않아도 됩니다 ㅎㅎ
1-2. 규제가 있는 선형 모델
훈련 데이터에만 완벽히 들어맞고 테스트 데이터에는 잘 맞지 않는 모델은 훈련 데이터에 과대적합되었다고 합니다.
과대적합되면 테스트 데이터에서의 성능이 좋지 않고 때문에 과대적합을 감소시킬 필요가 있습니다.
과대적합을 감소시키는 좋은 방법은 모델을 규제하는 것입니다.
선형 회귀 모델에서는 모델의 가중치를 제한함으로써 규제를 합니다.
비용함수에 가중치를 제한하는 방법에 따라 릿지 회귀, 라쏘 회귀, 엘라스틱넷 3가지로 나뉩니다.
하이퍼파라미터 알파는 모델을 얼마나 많이 규제할지 조절합니다.
①. 릿지 회귀

②. 라쏘 회귀

③. 엘라스틱넷

보통의 선형 회귀보다 적어도 규제가 약간 있는 것이 대부분의 경우에 좋으므로
일반적으로 평범한 선형 회귀보다는 규제를 가한 선형 회귀 모델을 쓰는 것이 좋습니다.
릿지가 기본적으로 사용되지만 쓰이는 특성이 몇 개뿐이라고 생각되면 라쏘나 엘라스틱넷이 낫습니다.
이 모델들은 불필요한 특성의 가중치를 0으로 만들어 줍니다.
또한, 특성 수가 훈련 샘플 수보다 많거나 특성 몇 개가 강하게 연관되어 있을 때는 보통 라쏘가 문제를 일으키므로 라쏘보다는 엘라스틱넷을 선호됩니다.
이렇게 지도학습의 회귀 중 선형 회귀에 대해 알아보았습니다.
'머신러닝' 카테고리의 다른 글
| 결정 트리 (Decision Tree) (0) | 2021.03.17 |
|---|---|
| 로지스틱 회귀 (Logistic Regression) (0) | 2021.03.15 |
| 사이킷런 (Scikit-Learn) : 파이썬의 대표적인 머신러닝 패키지 (0) | 2021.03.12 |
| 판다스 (Pandas) : 파이썬의 대표적인 데이터 처리 패키지 (1) | 2021.03.09 |
| 넘파이 (NumPy) : 행렬과 선형대수를 다루는 패키지 (0) | 2021.03.08 |