*해당 포스팅은 고려대학교 산업경영공학부 김성범 교수님의 Youtube 채널의 "[핵심 머신러닝] 불균형 데이터 분석을 위한 샘플링 기법" 자료를 보고 공부하며 작성한 글입니다. 그림들의 출처도 아래의 출처와 동일합니다.
출처: https://www.youtube.com/watch?v=Vhwz228VrIk&list=PLpIPLT0Pf7IoTxTCi2MEQ94MZnHaxrP0j&index=7
안녕하세요! 이전에 신용카드 사기 검출 실습에서 불균형 데이터를 다뤘었는데 불균형 데이터를 처리하는 다른 방법들은 무엇이 있을까 궁금하여 찾아보다
제가 강의를 자주 듣던 김성범 교수님 채널에서 불균형 데이터 분석을 위한 샘플링 기법 강의를 보고 공부하여 포스팅하게 되었습니다.
그럼 불균형 데이터를 처리하는 여러 샘플링 기법들에 대해서 알아보겠습니다.
1. 불균형 데이터란?
1-1. 개념
1-2. 문제점
2. 데이터를 조정해서 불균형 데이터를 해결하는 샘플링 기법들
2-1. 언더 샘플링
2-1-1. Random Sampling
2-1-2. Tomek Links
2-1-3. CNN Rule
2-1-4. One Sided Selection
2-1-5. 언더 샘플링의 장단점
2-2. 오버 샘플링
2-2-1. Resampling
2-2-2. SMOTE
2-2-3. Borderline SMOTE
2-2-4. ADASYN
2-2-5. GAN
2-2-6. 오버 샘플링의 장단점
1. 불균형 데이터란?
1-1. 개념
불균형 데이터란 정상 범주의 관측치 수와 이상 범주의 관측치 수가 현저히 차이나는 데이터를 말합니다.
예를 들면, 암 발생 환자가 암에 걸리지 않은 사람보다 현저히 적고, 신용카드 사기 거래인 경우가 정상 거래인 경우보다 현저히 적습니다.
이런 데이터들을 불균형 데이터라 볼 수 있습니다.
1-2. 문제점
정상을 정확히 분류하는 것과 이상을 정확히 분류하는 것 중 일반적으로 이상을 정확히 분류하는 것이 더 중요합니다.
왜냐하면 보통 이상 데이터가 target값이 되는 경우가 많기 때문입니다.

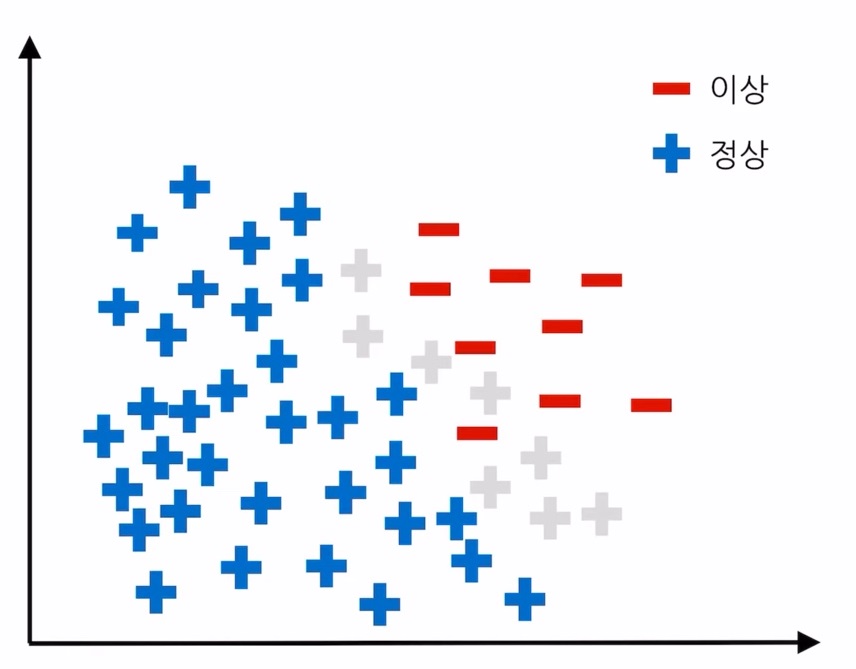
그림을 봤을 때 파란색은 정상 관측치이고 빨간색은 이상 관측치, 회색은 실제 이상 데이터의 분포를 나타낸 것입니다.
즉, 회색 원은 아직 관측되지 않은 모르는 데이터입니다.
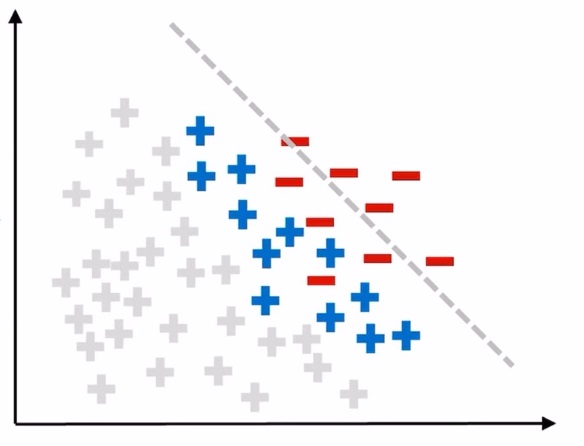
파란색과 빨간색의 데이터만 알고 있는 상태에서 학습을 시킬 경우 분류 경계선은 위의 그림과 같이 그어지게 됩니다.
하지만 경계선 왼쪽의 회색 원들은 실제로는 이상 데이터이기 때문에 정상 데이터로 오분류됩니다.
경계선은 파란색 원과 회색 원 사이에 그어져야 이상적인 경계선이라 할 수 있습니다.
즉, 불균형한 데이터 세트는 이상 데이터를 정확히 찾아내지 못할 수 있다는 문제점이 존재합니다.
2. 데이터를 조정해서 불균형 데이터를 해결하는 샘플링 기법들
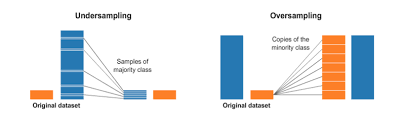
2-1. 언더 샘플링
언더 샘플링이란 다수 범주의 데이터를 소수 범주의 데이터 수에 맞게 줄이는 샘플링 방식을 말합니다.
2-1-1. Random Sampling
Random Sampling이란 말 그대로 다수 범주에서 무작위로 샘플링을 하는 것입니다.

3번의 Random Sampling을 한 결과인데 무작위로 샘플링을 하기 때문에 할 때마다 다른 결과를 얻는다는 단점이 존재합니다.
이를 보완하기 위해 나온 샘플링 방법이 Tomek Links 방법입니다.
2-1-2. Tomek Links
Tomek Links란 두 범주 사이를 탐지하고 정리를 통해 부정확한 분류경계선을 방지하는 방법입니다.
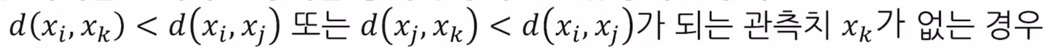
다른 클래스의 데이터 두 개를 연결했을 때 주변에 다른 임의의 데이터 Xk가 존재할 때
선택한 두 데이터에서 Xk까지의 거리보다 선택한 두 데이터 사이의 거리가 짧을 때 선택한 두 데이터 간의 링크를 Tomek Link라 부릅니다.

왼쪽의 경우 검은색 선은 Tomek Link가 될 수 없습니다.
왜냐하면 Xj 와 Xi 사이에 Xk 가 존재하게 되기 때문입니다.
오른쪽의 경우 Tomek Link라 볼 수 있습니다. 원본 데이터로 Tomek Link를 나타내면 다음과 같습니다.

보라색 묶음이 Tomek Link를 형성합니다. Tomek Links를 형성한 후, 다수 범주에 속한 관측치를 제거해 주어야 합니다.
다수 범주에 속한 관측치를 제거하여 언더 샘플링한 결과는 위의 그림과 같습니다.
2-1-3. CNN Rule
CNN Rule은 소수 범주에 속하는 데이터 전체와 다수 범주에 속하는 데이터 중 임의로 선택한 데이터 한 개 (A) 로 구성된 서브 데이터를 생성합니다.
그리고 다수 범주에 속하는 나머지 데이터들 중 하나씩 K=1 인 1-NN 방식을 이용하여
해당 데이터가 처음에 선택한 다수 범주 데이터 (A) 와 가까운지 아니면 소수 범주와 가까운지 확인하여 가까운 범주로 임시로 분류시킵니다.
이 과정이 끝나면 정상 분류된 다수 범주 관측치를 제거하여 언더 샘플링합니다.
K가 1이 아닌 K-NN 방식을 사용할 경우 모든 데이터가 이상 범주의 데이터로 분류되기 때문에 K는 1이어야 합니다.
CNN Rule을 통해 언더 샘플링한 결과는 위의 그림과 같습니다.
2-1-4. One Sided Selection
OSS (One Sided Selection) 방법은 Tomek Links 와 CNN Rule 을 합친 방법입니다.

OSS 방법을 이용하여 언더 샘플링한 결과는 위의 그림과 같습니다.
2-1-5. 언더 샘플링의 장단점
- 장점
다수 범주 데이터의 제거로 계산시간이 감소합니다.
- 단점
데이터 제거로 인한 정보 손실이 발생할 수 있습니다.
2-2. 오버 샘플링
오버 샘플링이란 소수 범주의 데이터를 다수 범주의 데이터 수에 맞게 늘리는 샘플링 방식을 말합니다.
2-2-1. Resampling
Resampling 방법은 소수 범주의 데이터 수를 다수 범주의 데이터 수와 비슷해지도록 증가시키는 방법입니다.
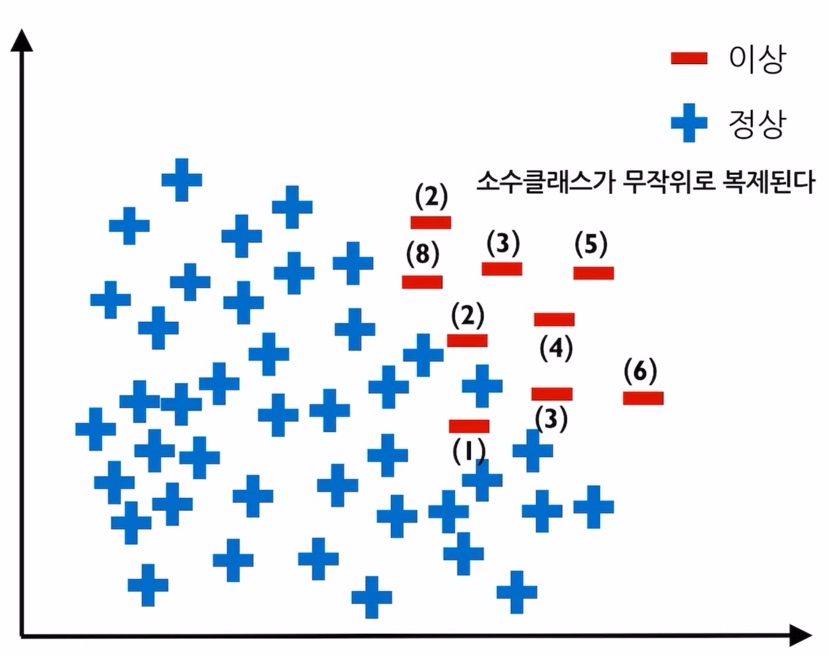
이때 소수 범주의 데이터는 무작위로 복제됩니다.
이 방법은 소수 범주에 과적합이 발생할 수 있다는 단점이 있고 이를 보완하기 위해 나온 방법이 SMOTE 방법입니다.
2-2-2. SMOTE
SMOTE 방법은 소수 범주에서 가상의 데이터를 생성하는 방법입니다.
K값을 정한 후 소수 범주에서 임의의 데이터를 선택한 후
선택한 데이터와 가장 가까운 K개의 데이터 중 하나를 무작위로 선정해 Synthetic 공식을 통해 가상의 데이터를 생성하는 방법입니다.
이 과정을 소수 범주에 속하는 모든 데이터에 대해 수행하여 가상의 데이터를 생성합니다.

주의할 점은 K값은 무조건 2 이상이어야 합니다.
왜냐하면 K가 1일 경우 데이터가 이상한 형태로 늘어나게 됩니다.
이 부분과 Synthetic 공식을 통해 가상의 데이터를 생성하는 과정에 대한 자세한 내용은 강의의 해당 부분을 참고하시면 좋을 것 같습니다.
2-2-3. Borderline SMOTE
Borderline SMOTE 방법은 Borderline 부분에 대해서만 SMOTE 방식을 사용하는 것입니다.
Borderline 을 찾는 것은 임의의 소수 범주의 데이터 한 개에 대해서 주변의 K개 데이터를 탐색하고 그중 다수 범주 데이터의 수를 확인합니다.
이때 다수 범주 데이터의 수가 K와 같을 경우 소수 범주의 데이터를 Noise 관측치라고 하며,
다수 범주 데이터의 수가 K/2 ~ K 에 속할 경우 Danger 관측치, 0 ~ K/2 에 속할 경우 Safe 관측치라고 합니다.
이 중 Danger 관측치에 대해서만 SMOTE를 적용하여 오버 샘플링을 진행합니다.

2-2-4. ADASYN
ADASYN 방법은 Borderline SMOTE 방법과 비슷하지만 샘플링 개수를 데이터 위치에 따라 다르게 설정하는 것이 차이점입니다.
먼저, 모든 소수 범주 데이터에 대해 주변의 K개의 데이터를 탐색하고 그중 다수 범주 데이터의 비율을 계산합니다.
계산된 각 비율들을 비율의 총합으로 나눠 스케일링을 진행합니다.

그 후 (다수 범주 데이터 수 - 소수 범주 데이터 수) 를 스케일링이 진행된 비율에 곱해주고
반올림된 정수의 값만큼 각 소수 범주 데이터 주변에 SMOTE 방식으로 가상 데이터를 생성합니다.

이 방법은 소수 범주 데이터 주변의 다수 범주 데이터의 수에 따라 유동적으로 생성이 가능하다는 장점이 있습니다.
세 가지의 SMOTE 방식으로 불균형한 데이터를 오버 샘플링한 결과는 조금씩 다르고 결과는 다음과 같습니다.

2-2-5. GAN
GAN (Generative Adversarial Nets) 는 생성자와 구분자로 구성되어 있고 모델은 딥러닝을 사용하는 최신 오버 샘플링 기법입니다.
무작위로 노이즈를 생성하고 생성자를 통해 가짜 샘플을 만듭니다.
그 후 구분자에서 진짜 샘플과 가짜 샘플을 판별하고 너무 쉽게 판별될 경우 생성자에게 피드백을 줍니다.
그러면 생성자는 더욱 진짜 샘플과 비슷한 가짜 샘플을 만들어내고 구분자에게 판별을 시킵니다.
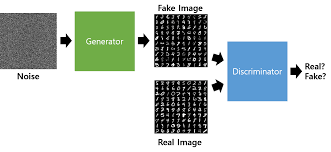
이렇게 생성자와 구분자가 서로 경쟁하며 업데이트되고 결국 가짜 샘플은 진짜 샘플과 매우 유사한 형태로 생성되게 됩니다.
참 재밌는 방식이라고 생각합니다.
2-2-6. 오버 샘플링의 장단점
- 장점
데이터를 증가시키기 때문에 정보 손실이 없습니다.
대부분의 경우 언더 샘플링에 비해 높은 분류 정확도를 보입니다.
- 단점
데이터 증가로 인해 계산 시간이 증가할 수 있으며 과적합 가능성이 존재합니다.
노이즈 또는 이상치에 민감합니다.
이렇게 데이터를 조정하여 불균형 데이터를 처리하는 여러 샘플링 기법들에 대해 알아보았습니다.
'데이터 핸들링 > 데이터 전처리' 카테고리의 다른 글
| High cardinality categorical feature에 효과적인 Mean target encoding (0) | 2021.07.19 |
|---|---|
| 결측치 (Missing Value) 처리하기 (0) | 2021.07.12 |