안녕하세요! 오늘은 데이터 인코딩 방법 중 Mean target 인코딩에 대해 알아보겠습니다.
카테고리형 피처가 매우 많은 종류의 카테고리를 가지고 있을 때
One-Hot 인코딩을 할 경우 새로운 컬럼이 너무 많이 생기게 되고 High Cardinality 피처를 모델에 너무 불균형하게 중요하게 만들어 Column Sampling 과정에 안 좋은 영향을 끼치게 됩니다.
그리고 보통 Feature Engineering 과정에서 피처들을 서로 결합해 새로운 피처를 생성하는데 이때, 새로운 High Cardinality 피처가 생성되게 됩니다.
그렇기 때문에 High Cardinality 카테고리형 피처를 숫자형으로 인코딩하기 위해 적합한 인코딩 방법이 필요하고 그것이 바로 Mean target 인코딩입니다.
그러면 이제, Mean target 인코딩에 대해 알아보겠습니다.
1. Mean target encoding이란?
2. Mean target encoding의 장단점
3. Mean target encoding에서 오버피팅을 개선하는 방법
3-1. Prior Probablity for Regularisation
3-2. K-Fold Regulation for Regularisation
3-3. Expanding Mean Regularisation
4. 결과
1. Mean target encoding이란?
Mean target 인코딩은 label 인코딩과 비슷하지만 target 값과 인코딩 값이 연관이 있다는 점에서 차이가 있습니다.
각 카테고리의 값을 학습 데이터의 target 값의 평균값으로 설정하는 것입니다.

예를 들어, 카테고리형 피처에 "category 1"의 데이터가 10개 있다고 가정하고 10개 중 8개가 target 값이 1이면 category 1을 0.8로 바꿔주는 것입니다.
label 인코딩과 피처 값을 수치적으로 인코딩한다는 점에서 비슷하지만 label 인코딩의 경우,
인코딩 값에 따른 순서 개념이 생겨서 모델이 순서 개념을 전제하여 학습하게 되어 선형 회귀 문제에는 부적합하다는 단점이 있습니다.
Mean target 인코딩의 경우, 각 카테고리 값을 수치적으로 인코딩하고 이 값이 예측값과 연관이 있기 때문에 더 많은 의미를 가지게 됩니다.
가까운 label 값들은 가까운 카테고리임을 알 수 있게 됩니다.
이로 인해 인코딩 된 값들은 less bias를 갖게 됩니다.
간단한 예시로 캐글의 IMDB 데이터 세트의 Genre 피처를 인코딩해보겠습니다.
import pandas as pd
df=pd.read_csv('IMDB-Movie-Data.csv')
df['Genre'].value_counts()
장르의 종류가 207개나 되는 것을 확인할 수 있습니다.
target을 수입으로 설정하고 Mean target 인코딩해보겠습니다.
target='Revenue (Millions)'
Genre_mean_target_encoded=df.groupby('Genre')[target].mean()
df['Genre_encoded']=df['Genre'].map(Genre_mean_target_encoded)
df[['Genre','Genre_encoded']].head(20)
매우 흥미로운 결과가 나왔습니다.
수치적인 값으로 인코딩을 했는데 값을 잘 살펴보면 비슷한 장르는 인코딩 된 값도 비슷한 것을 볼 수 있습니다.
0행과 4행을 보시면 3개의 장르 분류 중 마지막 하나만 다르고 인코딩 된 값은 209.23과 201.86으로 상당히 가까운 것을 확인할 수 있습니다.
즉, 위에서 말했던 가까운 label값들은 가까운 카테고리임을 확인할 수 있습니다.
2. Mean target encoding의 장단점
장점 (label 인코딩과 비교했을 때)
① label 인코딩의 경우 1000개의 데이터면 1000개의 label이 생기는데 Mean target 인코딩은 카테고리 종류의 수만큼 label이 생기므로 더욱 적은 split이 생기고 학습이 더욱 빠르게 이루어집니다.
② 인코딩된 label값이 target값과 관련된 의미를 가지게 되었으므로 less bias를 가집니다.
단점
① 구현과 검증이 까다롭습니다.
② 오버피팅이 일어나기 쉽습니다.
3. Mean target encoding에서 오버피팅을 개선하는 방법
3-1. Prior Probablity for Regularisation ( Smoothing )
오버피팅이 일어나는 한 가지 경우로 기존의 Mean target 인코딩은 하나의 label에 하나의 mean값만 사용하기 때문에
테스트 데이터의 해당 label값의 분포가 학습 데이터의 분포와 다르다면 오버피팅이 일어날 수밖에 없습니다.
극단적인 예로, 학습 데이터에 남자가 95명 여자가 5명이고 테스트 데이터에 남자가 50명 여자가 50명이라고 가정하면,
학습 데이터의 여자 5명이 테스트 데이터의 여자 50명을 대표하기 어렵다고 볼 수 있습니다.
그렇기 때문에 학습 데이터의 여자 5명의 치우쳐진 평균을 전체 평균에 가깝도록 해주면서 규제를 가하는 것이 Smoothing 입니다.

n_c는 카테고리의 샘플의 수, P_c는 카테고리의 target mean, P_gloabl은 전체 데이터의 target mean이고 alpha는 하이퍼 파라미터로 규제를 위한 값입니다.
alpha를 크게 할수록 규제를 강하게 하는 것이고 0이면 기존의 인코딩과 같아집니다.
Smoothing을 더해서 Genre 피처를 Mean target 인코딩을 해보겠습니다.
df['Genre_n_rows'] = df['Genre'].map(df.groupby('Genre').size())
global_mean = df[target].mean()
alpha = 0.5
def smoothing(n_rows, target_mean):
return (target_mean*n_rows + global_mean*alpha) / (n_rows + alpha)
df['Genre_encoded_smoothing'] = df.apply(lambda x:smoothing(x['Genre_n_rows'], x['Genre_encoded']), axis=1)
display(df[['Genre','Genre_encoded','Genre_encoded_smoothing']].head(20))
print('전체 target mean :',global_mean)
Smoothing을 한 결과를 보면 인코딩 된 label 값들이 전체적으로 전체 target mean 값에 가까워진 것을 확인할 수 있습니다.
3-2. K-Fold Regulation for Regularisation ( CV loop )
오버피팅이 일어나는 다른 이유로 Data Leakage문제가 있습니다.
학습 데이터에는 예측값에 대한 정보가 들어가면 안되는데 Mean target 인코딩 과정을 보면 인코딩 된 값에 예측값에 대한 정보가 포함되어 있습니다.
이러한 이유로 모델은 학습 데이터에 오비피팅 될 가능성이 생깁니다.
따라서, k-fold regulation을 통해 Data Leakage를 줄이고, 이전보다 label 값에 따른 인코딩 값을 fold 수만큼 더 다양하게 만들어 규제를 더해줍니다.
인코딩 값을 다양하게 만들면 트리가 만들어질 때, 더욱 세분화되어 나누어져서 더 좋은 훈련 효과를 기대할 수 있습니다.
3-3. Expanding Mean Regularisation
Expanding mean regularisation은 label 당 인코딩 되는 값을 더욱 많이 만드는 방법입니다.
CV loop에서는 인코딩 값이 fold의 수만큼 나오지만 더욱 다양하게 나오게 해서 트리가 더 잘 학습할 수 있게 하는 것입니다.
샘플의 수가 적은 카테고리일수록 더 많이 Randomization 되므로 오버피팅을 개선하는데 도움이 됩니다.
하지만 추가적으로 생성한 값이 노이즈일 수 있고 너무 많은 노이즈가 생성될 수 있어 모델의 성능을 저하시킬 수 있다는 단점이 존재합니다.
4. 결과
IMDB 데이터의 카테고리형 피처들을 인코딩하여 GBM을 통해 분류하고 성능을 평가한 결과를 확인해 보겠습니다.
결과는 https://www.kaggle.com/vprokopev/mean-likelihood-encodings-a-comprehensive-study에서 가져온 것이며
인코딩 방법은 label 인코딩, One-Hot 인코딩, Frequency 인코딩, Mean target 인코딩, Smoothing을 더한 Mean targe 인코딩,
여기에 k-fold regularisation을 더한 Mean target 인코딩, 여기에 expanding mean regularisation을 더한 Mean target 인코딩을 사용했습니다. 코드는 위의 링크를 참고하시면 됩니다.
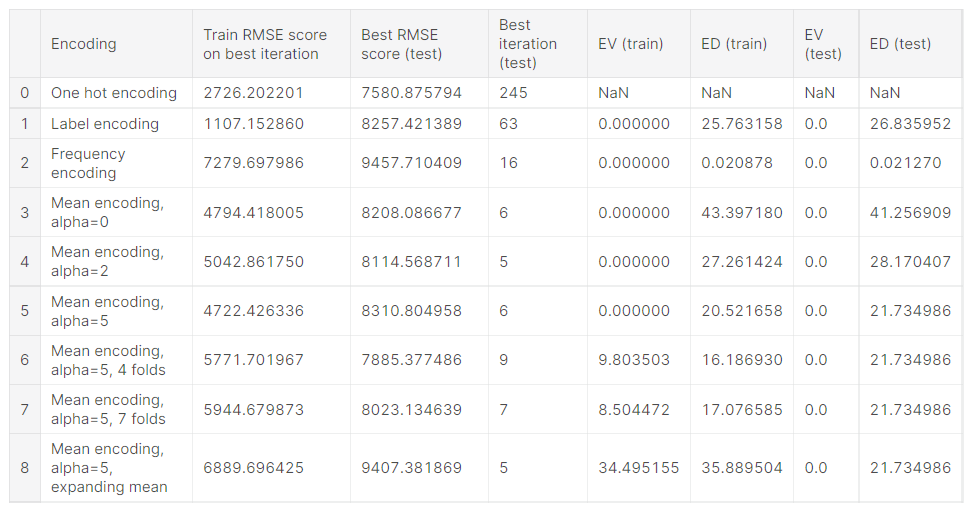
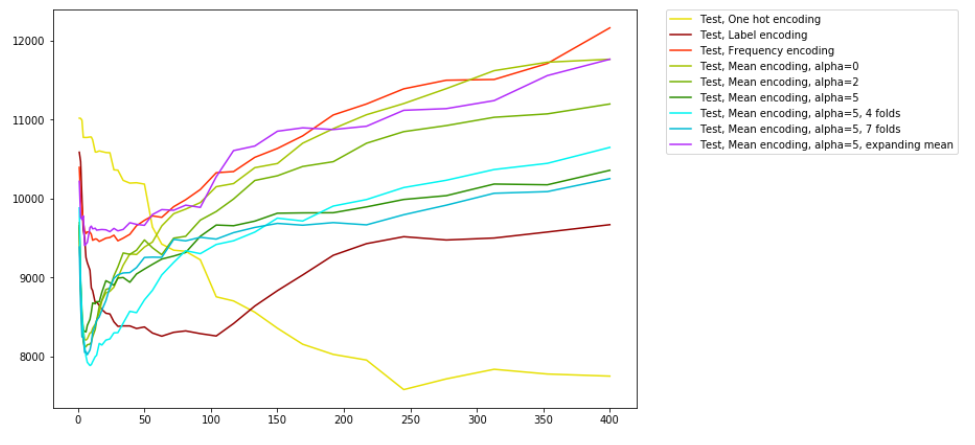
그래프를 살펴보면, Mean target 인코딩이 best score에 가장 빨리 도달한 것을 알 수 있고,
alpha=5로 smoothing 하고 4개의 fold로 k-fold regularisation 하여 인코딩했을 때 Mean target 인코딩 결과 중 가장 좋은 것을 확인할 수 있습니다.
여기서 위에서 말씀드린 Expanding mean regularisation의 단점이 나타났습니다.
보라색 선이 이에 해당하는데 너무 많은 노이즈가 더해져서 성능이 다른 Mean target 인코딩에 비해 현저히 떨어지는 것을 확인할 수 있습니다.
또한, One-Hot 인코딩이 시간은 오래 걸려도 가장 좋은 결과를 낸 것을 볼 수 있습니다.
하지만 Mean target 인코딩에 비해서는 시간이 너무 오래 걸리는 것으로 보입니다.
위 결과의 출처에서 다른 데이터들을 사용한 결과들을 보면 데이터에 따라 어떤 인코딩 방법이 가장 좋은지가 달라지는 것을 확인할 수 있습니다.
즉, 데이터의 형태에 따라 그에 맞는 인코딩 방법을 쓰는 것이 중요하다고 생각됩니다.
이 결과 또한 위 결과 출처에서 친절하게 알려주시고 있습니다.
이렇게 오늘은 다양한 인코딩 방법 중 Mean target 인코딩에 대해 알아봤습니다.
Reference
https://www.kaggle.com/vprokopev/mean-likelihood-encodings-a-comprehensive-study
https://dailyheumsi.tistory.com/120
'데이터 핸들링 > 데이터 전처리' 카테고리의 다른 글
| 결측치 (Missing Value) 처리하기 (0) | 2021.07.12 |
|---|---|
| 불균형 데이터 (imbalanced data) 처리를 위한 샘플링 기법 (3) | 2021.07.09 |