안녕하세요! 오늘은 딥러닝의 합성곱 신경망인 CNN에 대해서 알아보겠습니다.
1. CNN이란?
2. 합성곱 층 (Convolutional Layer)
3. 풀링 (pooling)
4. CNN의 전체 구조 및 과정
1. CNN이란?
CNN이란 Convolutional Neural Network의 약자로,
기존의 Deep Neural Network에서 이미지나 영상과 같은 데이터를 처리할 때 생기는 문제점들을 보완한 방법입니다.
기존의 DNN은 고해상도의 이미지를 처리할 때 입력 뉴런의 수가 급격하게 증가하게 되고 파라미터의 수도 급격하게 늘어납니다.

그림을 보면 16x16 이미지를 기존의 DNN으로 학습할 경우 28326개의 파라미터를 학습해야 합니다.
또한, DNN의 경우 기본적으로 1차원 형태의 입력 데이터를 사용합니다.
영상이나 이미지의 특성상 특정 픽셀은 주변 픽셀과 관련이 있는데
DNN은 1차원 형태의 입력 데이터를 사용하기 때문에 직렬화를 수행하면서 픽셀들의 상관관계를 잃게 됩니다.
따라서 DNN은 이미지나 영상의 전체 관계를 고려하지 못하게 되어 입력 데이터의 변형에 매우 취약해지게 됩니다.
이렇게 변형에 취약한 DNN은 변형된 이미지나 영상의 학습 데이터를 굉장히 많이 요구하게 됩니다.
이러한 문제를 해결하기 위해 나온 것이 CNN입니다.
CNN은 시각 피질의 국소 수용역과 시신경 세포의 방향 선택적 성격의 발견에 의해서 신경 생물학적인 영감을 받아 만들어진 기법입니다.
이 말은, 뉴런들이 일부 범위 안에 있는 시각 자극에만 반응한다는 뜻입니다.
이를 그림을 통해 살펴보겠습니다.
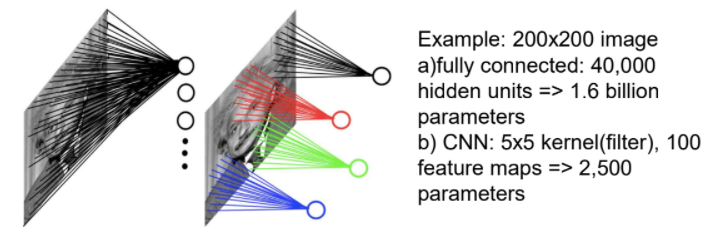
위의 그림을 보면 기존의 DNN으로 이미지를 학습할 때는 16억 개의 파라미터가 필요하지만,
오른쪽의 CNN은 뉴런이 특정 범위에 있는 이미지만 학습하기 때문에 훨씬 적은 양의 파라미터가 필요한 것을 확인할 수 있습니다.
CNN은 합성곱 층과 풀링 층으로 이루어져 있습니다.
이제, 합성곱 층과 풀링 층이 무엇인지 알아보겠습니다.
2. 합성곱 층 (Convolutional Layer)
합성곱 층은 CNN의 가장 중요한 요소입니다.
아래 그림을 보면, 첫 번째 합성곱 층은 위에서 말했듯이
이미지의 모든 픽셀에 연결되는 것이 아니라 뉴런의 수용장 안에 있는 픽셀에만 연결되어 있는 것을 볼 수 있습니다.
두 번째 합성곱 층에 있는 각 뉴런은 첫 번째 층의 작은 사각 영역 안에 위치한 뉴런에 연결됩니다.

합성곱 층이 어떻게 어떻게 작동하는지는 다음 그림을 통해 알아보겠습니다.
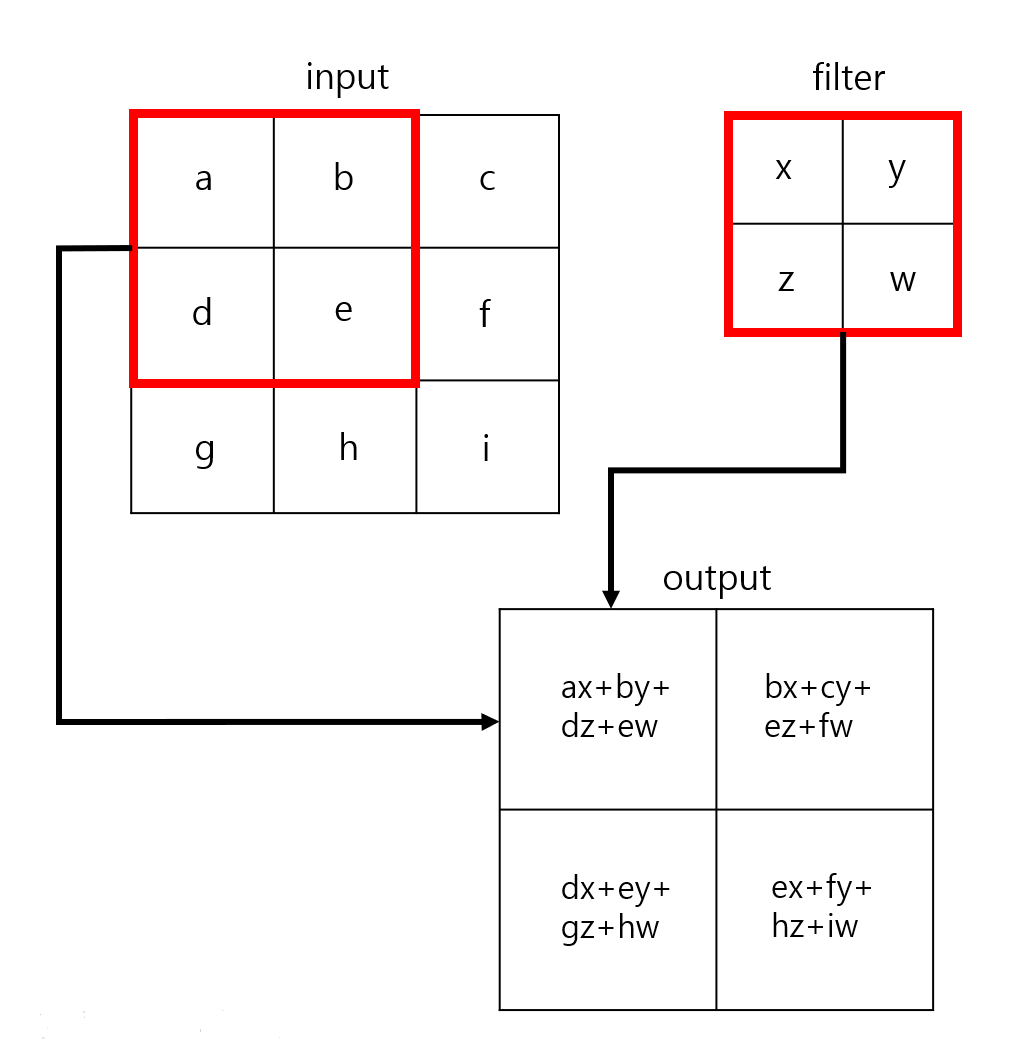
Convolution은 위의 그림과 같이 이루어집니다.
filter를 통해 부분적으로 이미지를 보는 것이고, 입력 데이터의 2x2 부분이 필터를 통해 하나의 값으로 출력되게 됩니다.
입력 데이터는 3x3에서 2x2로 출력됩니다.
이렇게 2x2 형태로 줄어들게 되면 데이터의 손실이 일어나게 됩니다.
이를 보완하기 위해서 zero padding이라는 것이 존재합니다.
데이터의 주변에 0을 붙여주어 필터를 통과한 후에도 데이터의 형태가 유지되도록 하는 것입니다.

zero padding을 하지 않는다면, 7x7 형태의 입력 데이터를 3x3 형태의 필터를 간격을 1씩 이동하며 통과하면 5x5 형태의 데이터가 출력되어야 하지만,
위의 그림처럼 zero padding을 해서 3x3 필터를 통과하면 7x7 형태가 유지된 채로 출력됩니다.
padding을 하면 데이터의 손실을 줄여줄 수 있지만, 원래 데이터에 없던 데이터를 붙였기 때문에 noise가 발생하게 됩니다.
noise의 영향을 최소화하기 위해 padding 값을 0으로 하는 것입니다.
noise가 발생함에도 데이터의 손실을 줄여주는 게 더 낫기 때문에 padding을 한다고 생각합니다.
여기서, filter가 이동하는 간격을 stride라고 부릅니다.
이 값은 임의로 지정할 수 있습니다.
출력 데이터의 크기는 입력 데이터의 크기, 필터의 크기, stride 값, padding 값에 의해 결정됩니다.
수식으로 표현하면 다음과 같습니다.

filter에 대해 좀 더 자세히 알아보겠습니다.
kernel이라고도 부르며, 층의 전체 뉴런에 적용된 하나의 필터는 하나의 특성맵을 만듭니다.
이 특성맵은 필터를 가장 크게 활성화시키는 이미지의 영역을 강조합니다.
아래 그림을 보면, 수직 필터의 경우 수직선만 강조되고 나머지는 희미한 특성맵을 출력하는 것을 확인할 수 있습니다.
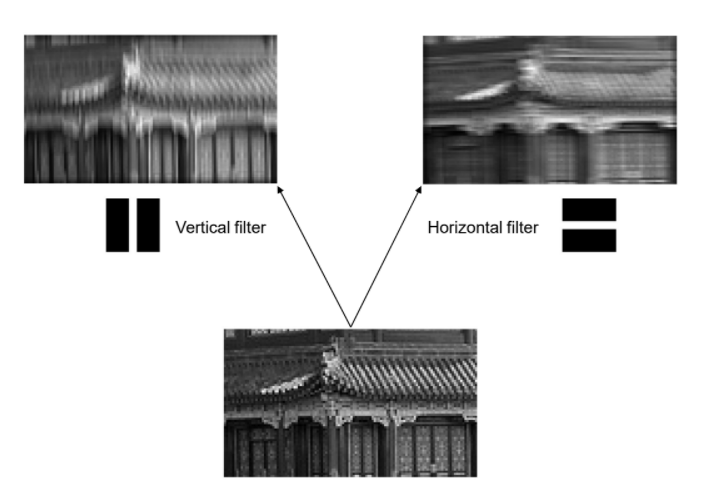
사실, 실제 합성곱 층은 여러 가지 필터를 가지고 필터마다 하나의 특성 맵을 출력 하므로 3D로 표현하는 것이 더 정확합니다.
하나의 합성곱 층이 입력에 여러 필터를 동시에 적용하여 입력에 있는 여러 특성을 감지할 수 있습니다.

위의 그림은 여러 가지 특성 맵으로 이루어진 합성곱 층과 3개의 컬러 채널을 가진 이미지의 모습입니다.
3D에서 특성맵들이 만들어지는 과정은 다음과 같습니다.


3차원의 입력 데이터가 필터를 통과하여 출력 데이터가 계산되는 방식은,
3개 채널의 입력 데이터와 3개 채널의 필터를 각각 Convolution하고 나온 3개의 출력값을 더해주는 것입니다.
이렇게 나온 출력 데이터가 하나의 특성맵이 되는 것입니다.
3. 풀링 (pooling)
이제 합성곱 층에 대해 알아봤으니 CNN의 다른 중요한 층인 풀링층에 대해서 알아보겠습니다.
풀링의 대표적인 방식은 두 가지가 있습니다.
Max-pooling과 Average-pooling이 있습니다.
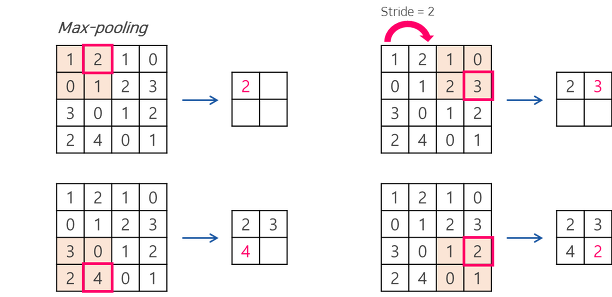
Max-pooling이란 해당 구역에서 최대값을 찾는 방법이고 위의 그림과 같습니다.
Average-pooling은 해당 구역의 평균값을 계산하는 방식입니다.
풀링을 하는 이유는 2가지가 있습니다.
① overfitting을 방지하기 위해
만약 우리에게 64x64인 이미지가 주어져 있다고 하고 이를 300개의 8x8 형태인 filter로 Convolution하면 (stride가 1이고
padding이 0이라고 가정),
한 개의 특성맵에 (64-8+1)x(64-8+1) = 3349개의 feature가 존재하고 이러한 특성맵이 합성곱 층에 300개 존재하므로 총 974,700개의 특성이 존재하게 됩니다.
이렇게 feature가 많다면 overfitting이 생길 가능성이 높습니다.
이를 pooling을 통해 데이터의 크기를 줄여 조절하는 것입니다.
② 평행이동이나 변형에 대해서 일정 수준의 불변성을 갖기 위해

위의 그림을 보면 데이터가 오른쪽으로 1칸 이동하고 Max-pooling을 해도, 원래 데이터에서 Max-pooling을 한 결과와 동일한 것을 알 수 있습니다.
어떤 물체의 구체적인 위치가 아닌 존재 여부가 더 중요할 땐 이런 일정 수준의 이동에 대한 불변성이 유용하게 작용합니다.
하지만 풀링은 데이터의 크기를 줄이기 때문에 파괴적이라는 단점도 존재합니다.
또한, 입력 이미지가 오른쪽으로 한 픽셀 이동했을 때 출력도 오른쪽으로 한 픽셀 이동해야 하는 시멘틱 분할 같은 작업에는 불변성이 필요하지 않습니다.
이러한 경우에는 입력의 작은 변화가 출력에서 그대로 상응되는 작은 변화로 이어지는 등변성이 중요합니다.
4. CNN의 전체 구조 및 과정
앞에서 CNN의 두 중요한 계층인 합성곱 층과 풀링 층에 대해 알아봤습니다.
이번에는 CNN의 전체 구조와 흐름에 대해 살펴보겠습니다.

입력 이미지를 Convolution과 Max-Pooling을 통해 깊이를 깊게하고 size를 줄여준 후, 4x4xn2의 데이터를 1차원의 데이터로 만듭니다.
1차원으로 만드는 것을 Flatten이라고 합니다.
이렇게 1차원으로 만든 데이터를 DNN 네트워크를 통해 최종 output을 출력합니다.
이렇게 영상과 이미지 인식 분야에 효과적인 CNN의 구조와 작동 방식에 대해 알아보았습니다.
CNN의 모델은 매년 발전하고 있고 ILSVRC 이미지넷 대회(https://image-net.org/)에서 우승한 모델들이 매년 에러율을 줄이고 있습니다.
앞으로 ILSVRC에서 우승한 모델들에 대해서도 공부해보고 기회가 된다면 포스팅도 해보도록 하겠습니다 : )
Reference
핸즈온 머신러닝(2판)
https://excelsior-cjh.tistory.com/180
https://hobinjeong.medium.com/
'딥러닝' 카테고리의 다른 글
| 텍스트 전처리와 RNN을 활용한 스팸 메일 분류 (1) | 2021.08.24 |
|---|---|
| LSTM(Long Short-Term Memory)과 GRU(Gate Recurrent Unit) (0) | 2021.08.21 |
| 딥 러닝의 가장 기본적인 시퀀스 모델 RNN (Recurrent Neural Network) (0) | 2021.08.19 |
| 기울기 소실과 폭주 (Gradient Vanishing & Exploding) (0) | 2021.08.12 |