안녕하세요! 오늘은 자연어 처리에서 많이 쓰이는 딥 러닝의 가장 기본적인 시퀀스 모델인 RNN에 대해 알아보겠습니다.
1. RNN이란?
2. RNN의 학습
3. 바닐라 RNN의 한계
1. RNN이란?
RNN이란 Recurrent Neural Network의 약자로, 순환 신경망을 뜻합니다.
RNN은 입력과 출력을 시퀀스 단위로 처리합니다.
시퀀스란 문장 같은 단어가 나열된 것을 뜻합니다.
이러한 시퀀스들을 처리하기 위해 고안된 모델을 시퀀스 모델이라 하며, 그중에서 RNN은 딥 러닝의 가장 기본적인 시퀀스 모델입니다.
RNN의 은닉층에서 활성화 함수를 통해 결과를 내보내는 역할을 하는 노드를 셀이라고 합니다.
이 셀은 이전의 값을 기억하려고 하는 일종의 메모리 역할을 수해하므로 메모리 셀이라고 부릅니다.
RNN은 이름에서 알 수 있듯이, 은닉층의 메모리 셀에서 나온 값이 다음 은닉층의 메모리 셀에 입력됩니다.
이 값을 은닉 상태라고 합니다.
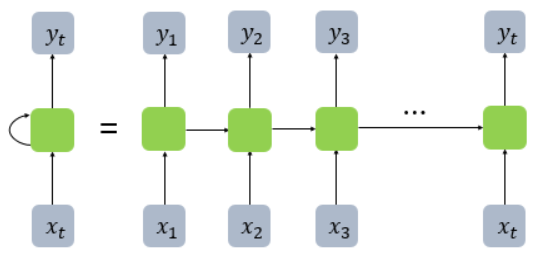
위의 그림을 보면 알 수 있듯이, 이전의 메모리 셀 출력 값과 현재의 입력 값 두 개가 입력으로 사용됩니다.
RNN은 입력과 출력의 길이를 다르게 설계할 수 있어 다양한 용도로 사용할 수 있는 장점이 있습니다.
① 일 대 다 (one-to-many)
하나의 입력에 대해 여러 개의 출력을 가지는 일 대 다 모델의 경우
하나의 이미지 입력에 대해서 사진의 제목을 출력하는 이미지 캡셔닝에 사용할 수 있습니다.
사진의 제목이 단어들의 나열이므로 시퀀스 출력입니다.

② 다 대 일 (many-to-one)
시퀀스 입력에 대해서 하나의 출력을 하는 다 대 일 모델은
입력 문서가 긍정적인지 부정적인지 판별하는 감성 분류나 정상 메일인지 스팸 메일인지 분류하는 스팸 메일 분류에 사용할 수 있습니다.

③ 다 대 다 (many-to-many)
시퀀스 입력에 대해 시퀀스 출력을 하는 다 대 다 모델의 경우 챗봇이나 번역기에 많이 쓰입니다.
개체명 인식이나 품사 태깅과 같은 작업 또한 다 대 다 모델에 속합니다.

RNN 층은 사용자의 설정에 따라 두 가지 종류의 출력을 내보냅니다.
메모리 셀의 최종 시점의 은닉 상태만을 리턴할 수 있고, 메모리 셀의 각 시점의 은닉 상태들을 모두 리턴할 수 있습니다.
각 시점의 모든 은닉 상태를 리턴하려면 RNN 층의 return_sequences 매개 변수를 True로 설정하면 가능합니다.
이때 은닉 상태(h)는 출력 값이 아니라 이 은닉 상태가 활성화 함수를 지난 것이 출력 값입니다.

2. RNN의 학습
RNN이 무엇인지 알아보았으니, RNN의 학습에 대해 알아보겠습니다.
RNN의 학습에는 back propagation의 확장인 BPTT가 사용됩니다.
BPTT는 Back Propagation Through Time의 약자로, 재귀적인 형태의 모델을 시간에 대해 펼쳐서 현재 시점의 에러를 최초 시점까지 전파해 학습하는 것입니다.


위의 그림은 RNN을 나타낸 것입니다.
U,V,W는 가중치를 뜻하고 x는 현재 시점의 입력 값, s는 은닉층의 메모리 셀의 출력 값, y는 해당 시점의 출력 값입니다.
이 신경망의 학습을 수식을 통해 알아보겠습니다.


위의 그림의 E는 각 시점의 Error를 뜻합니다.
첫 번째 식은 각 시점의 Error를 나타낸 식이고, 두 번째 식은 total loss는이전의 모든 시점의 Error를 합한 값임을 나타낸 식입니다.
위의 수식과 같이 RNN에서는 이전의 모든 시점의 Error를 활용하여 학습을 합니다.
이해하기 위한 예시로, t=3 시점에서 BPTT가 이루어지는 것을 살펴보겠습니다.


가중치 W가 모든 시점에서 메모리 셀의 출력 값(s)을 구할 때 사용되었기 때문에 위의 수식에서 처럼 k=0부터 3까지 계산하여 합하는 것입니다.
이렇게 학습 시에 앞의 시점으로 계속 전파가 일어나는데, 전파가 길어질수록 기울기 값이 0에 가까워지게 되는 기울기 소실 문제가 발생하게 됩니다.
※ 기울기 소실에 대한 설명은 제 블로그의 기울기 소실과 폭주 포스팅에 자세하게 설명해 놓았습니다.
https://casa-de-feel.tistory.com/36
3. 바닐라 RNN의 한계
바닐라 맛이 아이스크림의 가장 기본적인 맛을 나타내는 것처럼, RNN의 가장 단순한 형태를 바닐라 RNN이라고 말합니다.
바닐라 RNN은 위의 BPTT에서 보았듯이 시점이 길어질수록 앞의 정보가 뒤로 충분히 전달되지 못하는 현상이 발생합니다.
가장 중요한 정보가 앞 쪽의 시점에 위치할 경우 바닐라 RNN의 경우 앞 쪽의 중요한 정보가 뒤로 오면서 정보량의 손실이 일어나게 됩니다.
이를 RNN의 장기 의존성 문제라고 합니다.
이러한 문제를 보완한 RNN 모델로 장단기 메모리 LSTM과 게이트 순환 유닛 GRU가 있습니다.
LSTM과 GRU에 대해서는 다음 포스팅에서 다루도록 하겠습니다.
Reference
위키독스의 딥 러닝을 이용한 자연어 처리 입문 (https://wikidocs.net/48558)
핸즈온 머신러닝(2판)
https://newsight.tistory.com/94
'딥러닝' 카테고리의 다른 글
| 텍스트 전처리와 RNN을 활용한 스팸 메일 분류 (1) | 2021.08.24 |
|---|---|
| LSTM(Long Short-Term Memory)과 GRU(Gate Recurrent Unit) (0) | 2021.08.21 |
| 영상과 이미지 인식 분야에 탁월한 CNN (Convolutional Neural Network) (0) | 2021.08.16 |
| 기울기 소실과 폭주 (Gradient Vanishing & Exploding) (0) | 2021.08.12 |