학기를 시작하고 취업 준비를 시작하다 보니 포스팅에 속도가 줄어들게 되네요...ㅎ 그래도 공부한 내용들에 대해서 꾸준하게 기록해보도록 하겠습니다!
오늘 알아볼 내용은 토픽 모델링의 가장 대표적인 알고리즘인 잠재 디리클레 할당(Latent Dirichlet Allocation)인 LDA 알고리즘을 추천에 활용하는 방법입니다.
1. 디리클레 분포
2. LDA의 생성 과정
3. LDA를 추천에 적용
1. 디리클레 분포
토픽 모델링이란 문서의 집합에서 토픽을 추출하는 과정입니다.
LDA는 다음과 같이 주어진 문서와 각 문서가 어떤 토픽을 가지는지 확률 모형을 통해 표현합니다.

여기서 말하는 확률 모형이 디리클레 분포입니다.
디리클레 분포란 연속 확률분포의 하나로 k차원의 실수 벡터 중 벡터의 요소가 양수이며 모든 요소를 더한 값이 1인 경우에 대해 확률값이 정의되는 분포입니다.
\( x_1, ... , x_k \)가 모두 양의 실수이고 \( \sum_{i=1}^k x_i=1 \)을 만족할 때 주어진 양의 상수 \( \alpha_1, ... , \alpha_k \)에 대하여 디리클레 분포를 다음과 같이 정의할 수 있습니다.
$$f(x_1, ... , x_k ; \alpha_1, ... , \alpha_k) = \frac{1}{\mathbf{B}(\alpha)}\prod_{i=1}^k x_i^{(\alpha_i)-1}$$
$$\mathbf{B}(\alpha)=\frac{\sum_{i=1}^k \Gamma(\alpha_i)}{\Gamma(\sum_{i=1}^k \alpha_i)}$$
여기서 \( \mathbf{B}(\alpha) \)는 정규화 상수입니다.
k가 3일 때 \( \alpha \)에 따른 디리클레 분포를 나타내면 다음과 같습니다.

우측 하단의 디리클레 분포를 보면 \( \alpha \)가 \( x_3, x_2, x_1 \)순으로 높을 때 \( x_3 \)의 확률이 가장 높음을 확인할 수 있습니다.
\( \alpha \)의 값이 모두 같은 경우는\( x_1, x_2, x_3 \)의 확률이 동일함을 확인할 수 있습니다.
2. LDA의 생성 과정
① 토픽 개수 k를 설정
k개의 토픽은 모든 문서에 분포되어 있습니다.
② 문서에 있는 모든 단어를 k개 중 하나의 토픽에 랜덤으로 할당
한 단어가 한 문서에 두 번 이상 등장한다면 각 단어는 서로 다른 토픽으로 할당될 수도 있습니다.
③ 각 문서의 개별 단어에 대해 해당 단어를 제외한 나머지 단어들은 올바르게 토픽이 할당되어 있다는 가정하에 해당 단어에 토픽을 재할당
이 과정은 문서가 3개이고 토픽이 2개인 경우의 예시를 통해 알아보겠습니다.
doc1의 3번째의 cat을 재할당할 때 나머지 단어들은 토픽이 올바르게 할당되어 있다고 가정합니다.
이 단어의 토픽이 A일 확률은 아래와 같이 구합니다.
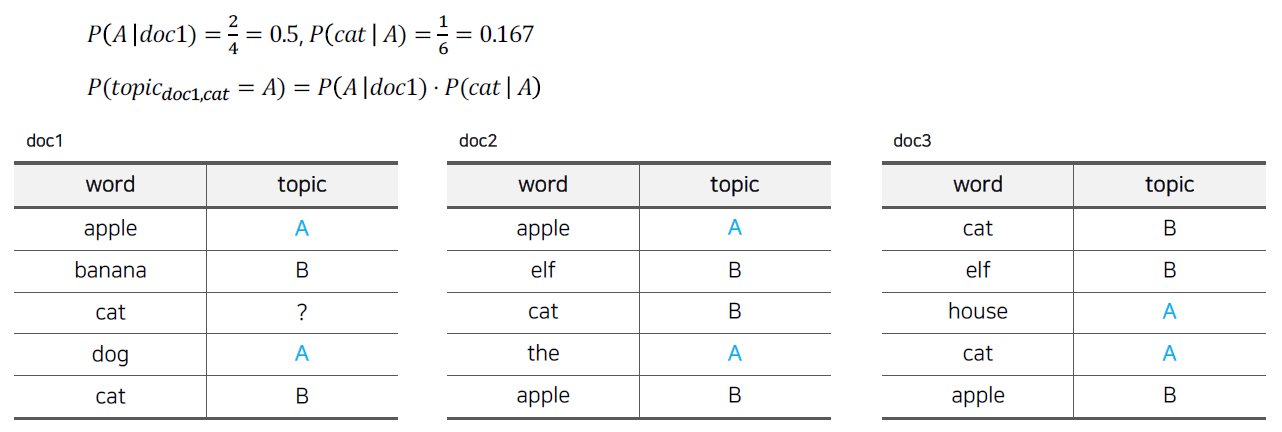
(doc1의 나머지 단어들 중 토픽이 A일 확률) X (토픽이 A일 때 단어가 cat일 확률) 로 해당 단어의 토픽이 A일 확률을 구합니다.
collapsed gibbs sampling 기법을 사용한 것입니다.
해당 단어의 토픽이 B일 확률도 같은 방법으로 구하며 아래와 같습니다.

해당 단어의 토픽이 A일 확률은 0.0835, B일 확률은 0.1875로 해당 단어는 토픽이 B일 확률이 높다고 볼 수 있습니다.
이렇게 모든 문서 내의 단어를 학습하면 문서의 토픽 분포와 토픽의 단어 분포가 디리클레 분포로 나옵니다.
문서의 토픽 분포는 \( \theta_d \sim Dir(\alpha) \)로 표현하고 토픽 개수인 k차원의 벡터이고 모든 원소의 합이 1이 됩니다.
여기서 \( \alpha \)는 토픽 분포 생성을 위한 디리클레 분포 파라미터이고 이 값이 클수록 토픽 간의 분포 차이가 적어집니다.
토픽의 단어 분포는 \( \phi_k \sim Dir(\beta) \)로 표현하고 전체 단어 개수인 N차원 벡터이고 마찬가지로 디리클레 분포이므로 모든 원소의 합이 1이 됩니다.
여기서 \( \beta \)는 토픽의 단어 분포 생성을 위한 디리클레 분포 파라미터이고 \( \alpha \)와 같은 역할을 합니다.
\( \alpha \)나 \( \beta \)는 확률값이 0이 되지 않도록 하는 smoothing의 역할을 하기 때문에 값이 커질수록 분포가 비슷해지는 것입니다.
LDA의 토픽 개수 k는 하이퍼 파라미터의 하나로 최적의 값을 구해야 하는데, 이는 Perplexity라는 지표를 사용하여 구할 수 있습니다.
LDA로부터 얻은 토픽 정보를 활용하여 얻은 문서 내 각 단어의 발생 확률이 클수록 잘 학습된 모델이라 할 수 있습니다.
전체 문서 내 모든 단어에 대한 발생 확률 \( p(W) \)를 구하면 \( Perplexity \propto exp(-\log (p(W))) \)라고 할 수 있습니다.
p(W)는 값이 높을수록 좋은 모델이기 때문에 Perplexity 값은 낮을수록 좋다고 할 수 있습니다.
따라서, 아래 그림처럼 토픽 개수 k를 바꿔가면서 Perplexity를 구한 뒤 가장 값이 적을 때의 k를 최적의 토픽 개수로 정하면 됩니다.

3. LDA를 추천에 적용
이제 토픽 모델링 알고리즘인 LDA를 추천에 적용하는 방법에 대해 알아보도록 하겠습니다.
문서를 유저로, 단어를 아이템으로 두고 LDA모델을 학습하면 유저는 토픽 분포를 갖게 됩니다.
또한, 각 토픽 별로 아이템의 분포가 생기기 때문에 개별 토픽에 대해서 가장 연관도가 높은 아이템이 무엇인지 알 수 있습니다.
이 과정을 통해 유저가 특정 토픽에 관심도가 높다면 그 토픽에 속한 연관도 높은 아이템을 추천해주는 것입니다.
유저-아이템에 대한 스코어 = 유저에 할당된 토픽의 확률 X 토픽이 아이템을 생성하는 확률이라고 표현할 수 있습니다.
예시를 통해 알아보도록 하겠습니다.
유저의 토픽 분포: \( \theta_u \) = [0.2, 0.8]
토픽의 아이템 분포: \( \phi_1 \) = [0.4, 0.2, 0.4], \( \phi_2 \) = [0.7, 0.1, 0.2]
일 때, 이 유저의 각 아이템에 대한 스코어는 아이템1 = 0.2*0.4 + 0.8*0.7, 아이템2 = 0.2*0.2 + 0.8*0.1, 아이템3 = 0.2*0.4 + 0.8*0.2 입니다.
따라서, 이 유저의 각 아이템에 대한 스코어는 0.64, 0.12, 0.24로 이 유저의 Top1 추천은 1번 아이템입니다.
이 방법을 일반 서빙이라고 부르며 아이템의 개수가 매우 많아지면 계산이 복잡해지기 때문에 빠른 서빙이라는 방법이 존재합니다.
빠른 서빙은 위의 예시에서 유저의 토픽 분포가 가장 높은 2번째 토픽을 할당하고 2번째 토픽 중 가장 확률이 높은 1번 아이템을 추천해 주는 방식입니다.
이 방식은 연산이 필요하지 않고 유저의 토픽 할당과 토픽의 Top N 아이템만 업데이트하면 됩니다.
LDA를 추천에 적용하는 방식은 많이 사용되는 방식은 아니지만 추천의 설명력이 뛰어나기 때문에 사용되는 경우도 있다고 합니다.
오늘은 토픽 모델링인 LDA에 대해 알아보고 이를 추천에 적용하는 방식에 대해 알아봤습니다.
LDA를 이용해서 추천 시스템을 직접 구현해보는 것도 이후에 포스팅하도록 하겠습니다 : )
Reference
러닝 스푼즈의 "비즈니스 Case와 딥러닝을 활용한 추천시스템 구현" 강의
LDA: https://ratsgo.github.io/from%20frequency%20to%20semantics/2017/06/01/LDA/
'추천시스템' 카테고리의 다른 글
| MAB(Multi Armed Bandit)를 활용한 추천 (0) | 2021.10.14 |
|---|---|
| TF-IDF를 활용한 컨텐츠 기반 필터링 (Content-based Filtering) (0) | 2021.08.23 |
| 내가 추천 시스템을 공부하는 이유 (0) | 2021.08.22 |